You are viewing an older version of this section. View current production version.
Pipelines Overview
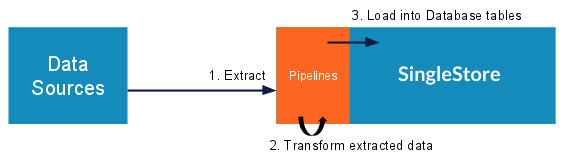
SingleStore Pipelines is a SingleStore DB database feature that natively ingests real-time data from external sources. As a built-in component of the database, Pipelines can extract, transform, and load external data without the need for third-party tools or middleware. Pipelines is robust, scalable, highly performant, and supports fully distributed workloads.
Pipelines support Apache Kafka, Amazon S3, Azure Blob, Filesystem, Google Cloud Storage and HDFS data sources.
Pipelines natively support the JSON, Avro, and CSV data formats.
Overview
All database products provide native mechanisms to load data. For example, SingleStore DB can natively load data from a file, a Kafka cluster, cloud repositories like Amazon S3, or from other databases. However, modern database workloads require data ingestion from an increasingly large ecosystem of data sources. These sources often use unique protocols or schemas and thus require custom connectivity that must be updated regularly.
The challenges posed by this dynamic ecosystem are often resolved by using middleware – software that knows how to deal with the nuances of each data source and can perform the process of Extract, Transform, and Load (ETL). This ETL process ensures that source data is properly structured and stored in the database.
Most ETL processes are external, third-party systems that integrate with a database; they’re not a component of the database itself. As a result, ETL middleware can introduce additional problems of its own, such as cost, complexity, latency, maintenance, and downtime.
Unlike external middleware, SingleStore Pipelines is a built-in ETL feature of the core SingleStore DB Database. Pipelines can be used to extract data from a source, transform that data using arbitrary code, and then load the transformed data into SingleStore DB.
Features
The features of SingleStore Pipelines make it a powerful alternative to third-party ETL middleware in many scenarios:
- Scalability: Pipelines inherently scales with clusters as well as distributed data sources like Kafka and cloud data stores like Amazon S3.
- High Performance: Pipelines data is loaded in parallel from the data source to SingleStore DB leaves, which improves throughput by bypassing the aggregator. Additionally, Pipelines has been optimized for low lock contention and concurrency.
- Exactly-once Semantics: The architecture of Pipelines ensures that transactions are processed exactly once, even in the event of failover.
- Debugging: Pipelines makes it easier to debug each step in the ETL process by storing exhaustive metadata about transactions, including stack traces and
stderrmessages.
Use Cases
SingleStore Pipelines is ideal for scenarios where data from a supported source must be ingested and processed in real time. Pipelines is also a good alternative to third-party middleware for basic ETL operations that must be executed as fast as possible. Traditional long-running processes, such as overnight batch jobs, can be eliminated by using Pipelines.
Terms and Concepts
SingleStore Pipelines uses the following terminology to describe core concepts:
- Data Source: A data source is any system that provides a way to access its data. A data source requires a matching extractor that knows how to communicate with it.
- Extractor: An extractor is the core Pipelines component that extracts data from a data source. Extractors provide a connection to the data source by communicating via supported protocols, schemas, or APIs.
- Transform: A transform is a user-defined program that executes arbitrary code to transform extracted data into JSON, Avro, or CSV format. The transformed data is then written into the specified table in the database.
- Pipeline: A pipeline is a conceptual term that represents a single instance of three unified components:
- A connection to a data source,
- The extractor being used, e.g. Kafka Extractor, and
- The transform that is converting the data (Optional)
Supported Data Sources
| Data Source | Data Source Version | SingleStore DB (MemSQL) Version |
|---|---|---|
| Apache Kafka | 0.8.2.2 or newer | 5.5.0 or newer |
| Amazon S3 | N/A | 5.7.1 or newer |
| Filesystem Extractor | N/A | 5.8.5 or newer |
| Azure Blob | N/A | 5.8.5 or newer |
| HDFS | 2.2.x or newer | 6.5.2 or newer |
| Google Cloud Storage | N/A | 7.1.0 or newer |
For more information, see Extractors.
Pipelines Scheduling
SingleStore DB supports running multiple pipelines in parallel. Pipelines will be run in parallel until all SingleStore DB partitions have been saturated. For example, consider a SingleStore DB cluster with 10 partitions. With this architecture, it is possible to run 5 parallel pipelines using 2 partitions each, 2 pipelines using 5 partitions each, and so on.
If the partition requirements of any two pipelines exceed the total number of SingleStore partitions, each pipeline will be run serially in a round robin fashion. For example, consider a SingleStore DB cluster with 10 partitions, and 3 pipelines. Let’s say the first batch of pipelines P1, P2, and P3 requires 4, 8, and 4 partitions, respectively. The pipelines are scheduled concurrently with the aim of saturating the partitions in a SingleStore DB cluster. Hence, the scheduler will run pipelines P1 and P3 in parallel to process their first batch. And then, it will run pipeline P2 serially, because the sum of number of partitions required by P2 and any other pipeline (P1 or P3) is greater than the number of partitions in the cluster (10 partitions). You can specify the maximum number of pipeline batch partitions that can run concurrently using the pipelines_max_concurrent_batch_partitions engine variable. Note that how many partitions a pipeline uses is dependent on the pipeline source.
Configuring Pipelines
You configure SingleStore Pipelines by setting engine variables. Pipelines sync variables are listed here and Pipelines non-sync variables are listed here.
See Also
- Data Ingest Training that Covers Pipelines
- Kafka Pipelines Overview
- Kafka Pipelines Quickstart
- S3 Pipelines Overview
- S3 Pipelines Quickstart
- Filesystem Pipelines Overview
- Filesystem Pipelines Quickstart
- Azure Blob Pipelines Overview
- Azure Blob Pipelines Quickstart
- HDFS Pipelines Overview
- Google Cloud Storage Quickstart
- Google Cloud Storage Overview

