You are viewing an older version of this section. View current production version.
Shard Keys
Every distributed table has exactly one shard key, or shard index. This functions like a normal table index, and can contain any number of columns. When you run CREATE TABLE to create a table, you can specify a shard key for the table. If you don’t specify a shard key, the default shard key is used.
A table’s shard key determines in which partition a given row in the table is stored. When you run an INSERT query, the aggregator computes the hash value of the values in the column or columns that make up the shard key, does a modulo operation to get a partition number, and directs the INSERT query to the appropriate partition on a leaf machine.
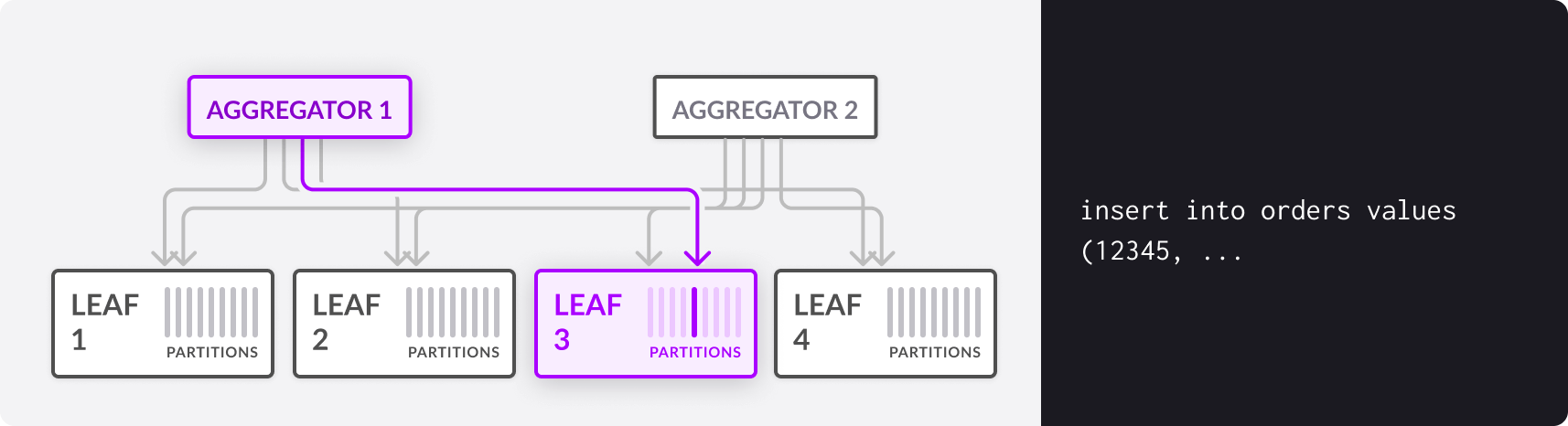
DML queries that fully match the shard key can be routed directly to a single partition on a single leaf server. Group-by queries where the set of keys are guaranteed to not overlap between partitions can be executed in parallel on the leaves, with the results streamed back without any additional processing on the aggregator.
Any two rows with the same shard key value are guaranteed to be on the same partition.
SingleStore DB requires that any PRIMARY or UNIQUE index must be identical to or a superset of the shard key. Rows which might have a primary key conflict must map to the same partition in order for uniqueness to be enforced.
Choosing an appropriate shard key is important for minimizing data skew.
Types of Shard Keys
Default Shard Key
If no shard key is specified, the shard key becomes the primary key. If no primary key or shard key is specified for a given table, the shard key defaults to being keylessly sharded. To accomplish this, you can either specify no keys, or use shard key() as follows. This also applies to columnstore tables that don’t specify a shard key.
CREATE TABLE t1(a INT, b INT);
CREATE TABLE t1(a INT, b INT, SHARD KEY());
In most cases, keyless sharding will result in uniform distribution of rows across partitions. Cases involving INSERT … SELECT statements are the exception to this.
Primary Key as the Shard Key
If you create a table with a primary key and no explicit shard key, the PK will be used as the shard key by default.
CREATE TABLE clicks (
click_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
page_id INT,
ts TIMESTAMP
);
Non-Unique Shard Key
The syntax for a non-unique shard key is SHARD KEY (col1, col2, ...). For example:
CREATE TABLE clicks (
click_id BIGINT AUTO_INCREMENT,
user_id INT,
page_id INT,
ts TIMESTAMP,
SHARD KEY (user_id),
PRIMARY KEY (click_id, user_id)
);
In this example, any two clicks by the same user will be guaranteed to be on the same partition. You can take advantage of this property in query execution for efficient COUNT(DISTINCT user_id) queries, which knows that any two equal (non-distinct) user_id values will never be on different partitions.
Note that even though click_id will be unique, we still have to include user_id in the primary key.
Choosing a Shard Key
See the Optimizing Table Data Structures guide for information on how to choose a shard key.
Data Skew
Data skew occurs when data is unevenly distributed across partitions.
Choosing an appropriate shard key for a table is important for mimimizing data skew.
Refer to this topic for information on detecting and resolving data skew.
Related Topics
- Training: SingleStore DB Sharding and Shard Keys

