You are viewing an older version of this section. View current production version.
Connecting to StreamSets
Streamsets: Streamsets is an open-source, desktop platform for hybrid cloud that enables data movement architectures at scale. For details, see the StreamSets website.
SingleStore Fast Loader: The SingleStore Fast Loader destination uses a JDBC connection to insert data into a SingleStore DB or MySQL database table with a LOAD statement. In pipelines that insert data into SingleStore DB or MySQL, you can use the SingleStore Fast Loader destination rather than the JDBC Producer destination for faster performance.
This topic describes how to connect StreamSet to SingleStore DB using SingleStore Fast Loader.
The certification matrix below shows the latest versions tested for SingleStore DB and StreamSets:
| Certification Matrix | Versions |
|---|---|
| StreamSets Data Collector | 3.13.0 |
| SingleStore DB | 7.1 |
Prerequisites
The following prerequisites need to be satisfied before making the connection:
-
Download and install StreamSets by following the instructions here.
-
Make sure the SingleStore DB Cluster is running on the server.
-
Open a web browser and connect to StreamSets: http://<IP Address of the server running the StreamSets service>:18630/
-
To install and configure the SingleStore Fast loader, go here.
Connecting StreamSets to SingleStore DB via Fast Loader
StreamSets can be connected to SingleStore DB via Fast Loader by creating different types of pipelines. This document provides the connection details for the following pipelines:
- Hadoop
- Kafka
- Filesystem
Perform the following steps first, then follow the specific instructions for your respective pipeline below.
-
Open the following URL: http://< IP Address of the server running the StreamSets service >:18630/
-
Enter the username and password to log in. The default is admin/admin
-
On the Get Started page, click + Create New Pipeline to create a new Pipeline.
-
Add a title and description for the new pipeline and click Save.
Pipeline from Hadoop Source to SingleStore DB Using the Fast Loader
-
Under Select Origin on the right hand side panel, select Hadoop FS Standalone.
-
Provide the Origin Name and select ‘Send to error’ for the On Record Error field.
-
On the connections tab enter the Hadoop File system URI in the following format: hdfs://<IP Address of the server running the Hadoop system>:9000/
-
Click on the Fields tab and provide the Hadoop file system details.
-
In the Data Source tab, provide the data source details.
-
From the right pane select SingleStore Fast Loader as the destination type and configure as below:
General
- Name: Name of destination
- On Record Error: Sent to error
JDBC
- JDBC Connection string
- Schema Name and Table Name
NOTE: Do the Field to column mapping for all the columns present in the target table.
-
Connect Hadoop FS Standalone origin to SingleStore Fast Loader destination.
-
Start the pipeline and data processing will start.
You are now ready to move the data.
Pipeline from Kafka Source to SingleStore DB Using the Fast Loader
-
Under Select Origin on the right-hand side panel, select Kafka Consumer as the origin type and configure as below:
General
- Name: Name of Origin
- On Record Error: Sent to error
Kafka
- Broker URI: ip-< IP address of the machine running Kafka >:9092
- Zookeeper URI: ip-< IP address of the machine running Kafka >:2181
- Consumer Group: < Name of the consumer group >
- Topic: < Name of the Kafka topic >
Data Format:
- Data format: Delimited
- Delimiter Format Type: Default CSV (ignore empty lines)
- Header line: No Header Line
-
From the right pane select SingleStore Fast Loader as the destination type and configure as below:
General
- Name: Name of destination
- On Record Error: Sent to error
JDBC
- JDBC Connection string
- Schema Name and Table Name
- Field to Column Mapping: < Do mapping of all columns where data is going to load >
- Default Operation: Insert
Credentials:
- Username: < DB user >
- Password: < DB password >
NOTE: Do the Field to column mapping for all the columns present in the target table.
-
Connect Kafka Consumer Origin to SingleStore Fast Loader.
-
Start the pipeline by clicking on the option present above the left pane.
You are now ready to move the data.
Pipeline from Filesystem Source to SingleStore DB Using the Fast Loader
-
Under Select Origin on the right-hand side panel, select Directory as the origin type and configure as below:
General
- Name: Name of Origin
- On Record Error: Sent to error
Files
- File Directory: < Directory path where file exists >
- File Name Pattern: *.csv
Data Format:
- Data format: Delimited
- Delimiter Format Type: Default CSV (ignore empty lines)
- Header line: With Header Line
-
From the right pane select SingleStore Fast Loader as the destination type and configure as below:
General
- Name: Name of destination
- On Record Error: Sent to error
JDBC
- JDBC Connection string
- Schema Name and Table Name
- Field to Column Mapping: < Do mapping of all columns where data is going to load >
- Default Operation: Insert
Credentials:
- Username: < DB user >
- Password: < DB password >
NOTE: Do the Field to column mapping for all the columns present in the target table.
-
Connect Directory Origin to SingleStore Fast Loader.
-
Start the pipeline by clicking on the option present above the left pane.
You are now ready to move the data.
SingleStore Fast Loader vs the JDBC Connector
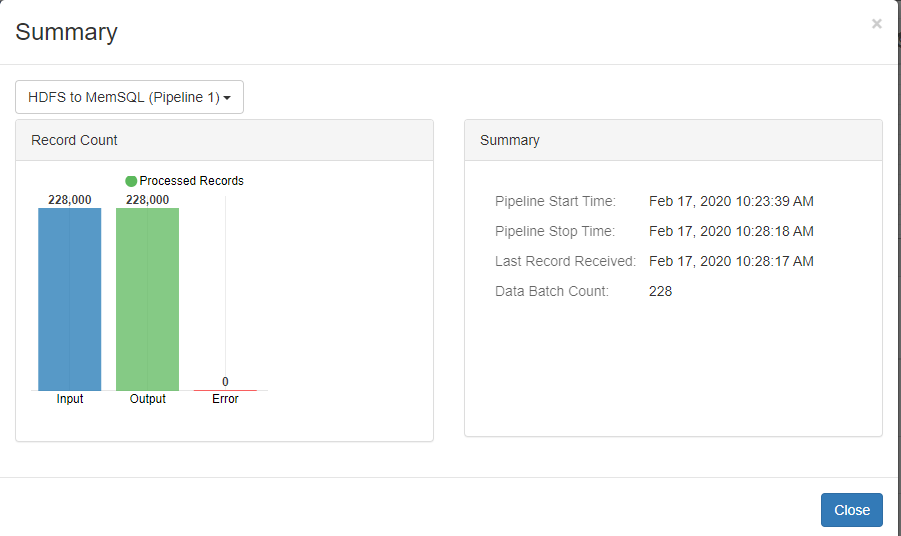
The SingleStore fast loader as the name indicates, processes the data at a much higher rate as compared with the JDBC connectors. The images below show the comparison between the Fast loader and JDBC connector:
Origin: Hadoop File system
Destination: JDBC Producer
Records/Sec: 818
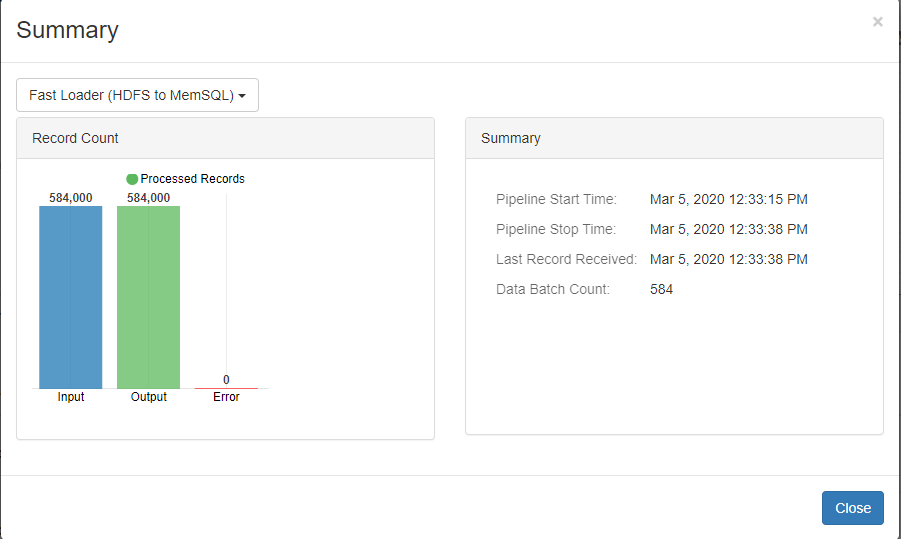
Origin: Hadoop File system
Destination: SingleStore Fast Loader
Records/Sec: 25391
Error and Logs
Accessing Error Messages
Informational and error messages display in different locations based on the type of information:
Pipeline configuration issues
The Data Collector UI provides guidance and error details as follows:
- Issues found by implicit validation display in the Issues list.
- An error icon displays at the stage where the problem occurs or on the canvas for pipeline configuration issues.
- Issues discovered by explicit validation display in a warning message on the canvas.
Runtime error information
- In the canvas, the pipeline displays error record counts for each stage generating error records.
- On the Errors tab, you can view error record statistics and the latest set of error records with error messages.
Data Collector errors
You can view information and errors related to the general Data Collector functionality in the Data Collector log. You can view or download the logs from the Data Collector UI.
Frequently Asked Questions
Pipeline Basics
When I go to the Data Collector UI, I get a “Webpage not available” error message.
The Data Collector is not running. Start the Data Collector.
Why isn’t the Start icon enabled?
You can start a pipeline when it is valid. Use the Issues icon to review the list of issues in your pipeline. When you resolve the issues, the Start icon becomes enabled.
The data reaching the destination is not what I expect - what do I do?
If the pipeline is still running, take a couple snapshots of the data being processed, then stop the pipeline and enter data preview and use the snapshot as the source data. In data preview, you can step through the pipeline and see how each stage alters the data.
If you already stopped the pipeline, perform data preview using the origin data. You can step through the pipeline to review how each stage processes the data and update the pipeline configuration as necessary.
You can also edit the data to test for cases that do not occur in the preview data set.
Data Preview
Why isn’t the Preview icon enabled?
You can preview data after you connect all stages in the pipeline and configure required properties. You can use any valid value as a placeholder for required properties.
Why doesn’t the data preview show any data?
If data preview doesn’t show any data, one of the following issues might have occurred:
- The origin might not be configured correctly.
- The origin might not have any data at the moment.

