You are viewing an older version of this section. View current production version.
How the Columnstore Works
In SingleStore DB there are a few concepts that are important to understand in order to make the best possible use of the columnstore:
- Clustered columnstore index - A clustered columnstore index represents the full table structure and is its primary storage.
- Columnstore key column(s) - When creating a columnstore index, one or more columns need to be defined as the key column(s) for the columnstore index. The data in the columnstore is stored in key column order. Selecting a good columnstore key can significantly improve performance as covered later in this section.
- Row segment - A row segment is a set of rows within a columnstore index that are stored together, each of which is made up of column segements. SingleStore DB stores the metadata for each row, which includes the total row count for a given segment, as well as a bitmask tracking which rows have been deleted.
- Column segment - Each row segment contains a column segment for every column in a table. The column segment is the unit of storage for a columnstore table and contains all values for a specific column within the row segment. Values in column segments are always stored in the same logical order across column segments within the same row segment. SingleStore stores in memory the metadata for each column segment, which includes the minimum and maximum values contained within the segment. This metadata is used at query execution time to determine whether a segment can possibly match a filter, a process known as
segment elimination. - Sorted row segment group - A sorted row segment group represents a set of row segments that are sorted together on the columnstore key column(s). This means that within a sorted row segment group there will be no row segments with overlapping value ranges for the column(s) that make up the key for the columnstore index. New segment groups are formed when more segments are created after running
INSERT,LOAD, orUPDATEqueries on the table. Information on how this affects query performance and how to minimize the number of sorted row segment groups is covered later in this section.
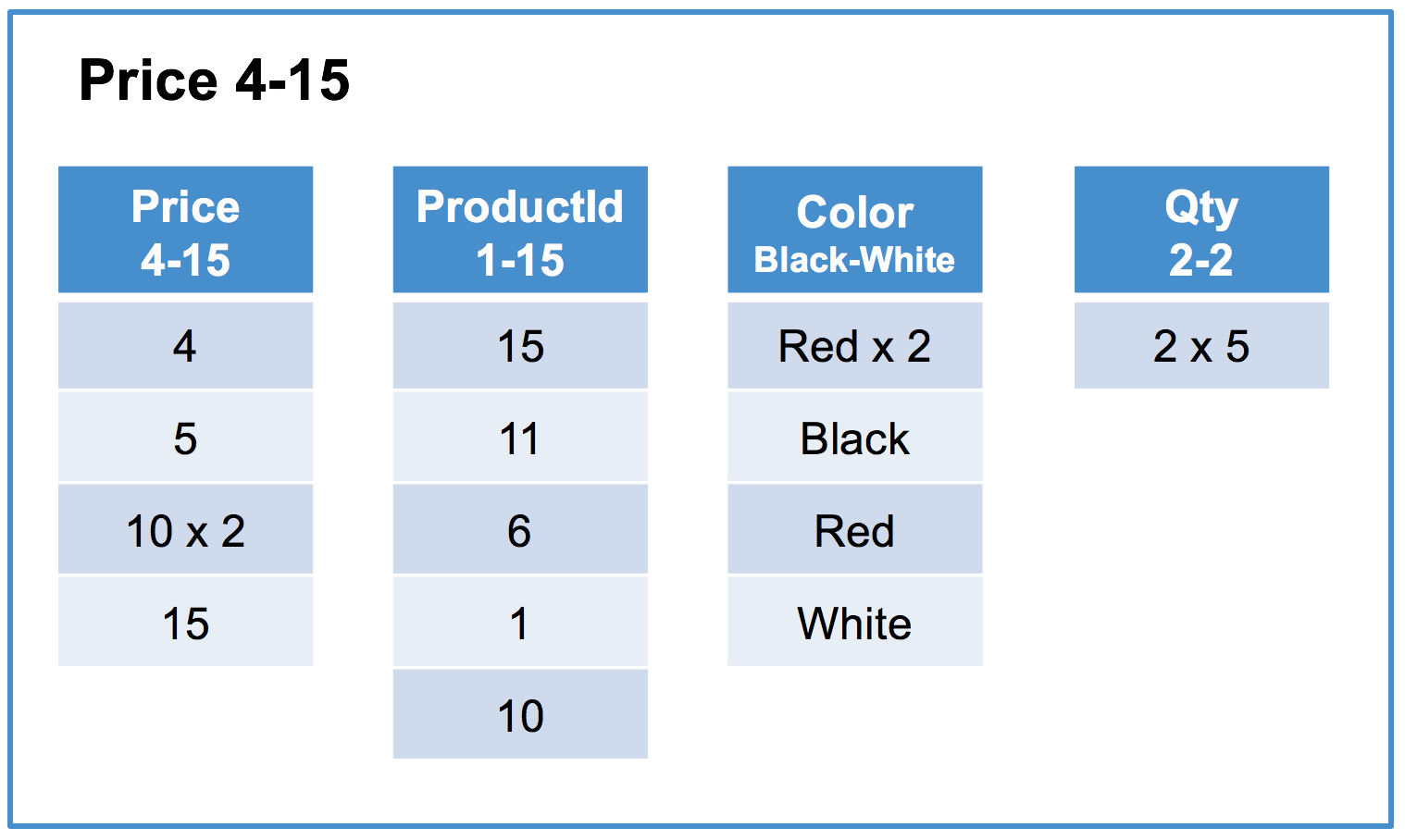
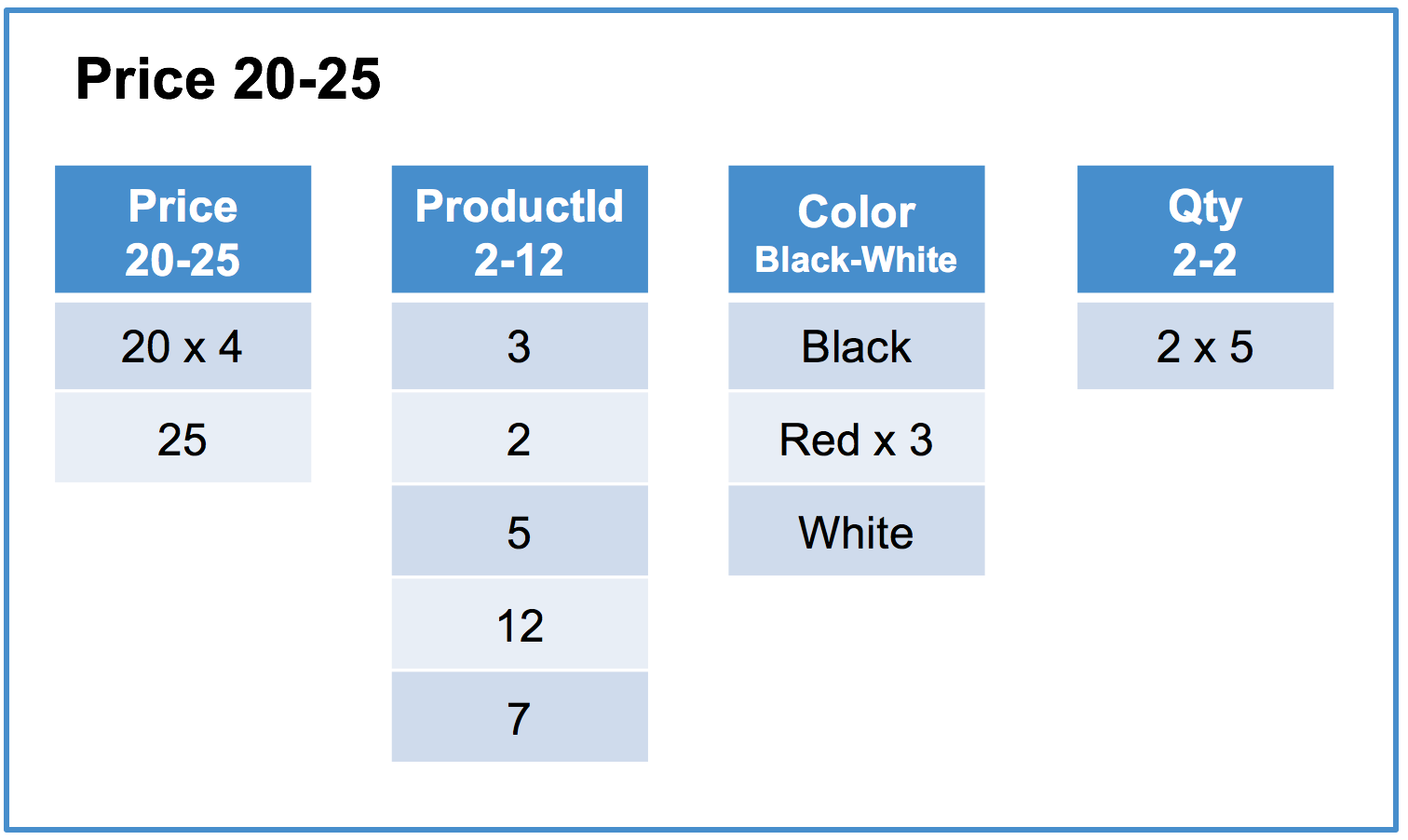
Below is an example of a SingleStore DB columnstore index on the Products table using the Price column as its key. See Choosing a Columnstore Key for an example of how to create the table.
Column segments typically contain on the order of hundreds of thousands of rows. In this example, the segment size is 5 rows for readability.
Each row segment contains one column segment per column in the table. For simplicity, this example contains the initial load of the table and has a single sorted row segment group.
Logical table and rowstore representation
| ProductId | Color | Price | Qty |
|---|---|---|---|
| 1 | Red | 10 | 2 |
| 2 | Red | 20 | 2 |
| 3 | Black | 20 | 2 |
| 4 | White | 30 | 2 |
| 5 | Red | 20 | 2 |
| 6 | Black | 10 | 2 |
| 7 | White | 25 | 2 |
| 8 | Red | 30 | 2 |
| 9 | Black | 50 | 2 |
| 10 | White | 15 | 2 |
| 11 | Red | 5 | 2 |
| 12 | Red | 20 | 2 |
| 13 | Black | 35 | 2 |
| 14 | White | 30 | 2 |
| 15 | Red | 4 | 2 |
Sorted row segment group #1 of 1
Row segment #1 of 3
Row segment #2 of 3
Row segment #3 of 3
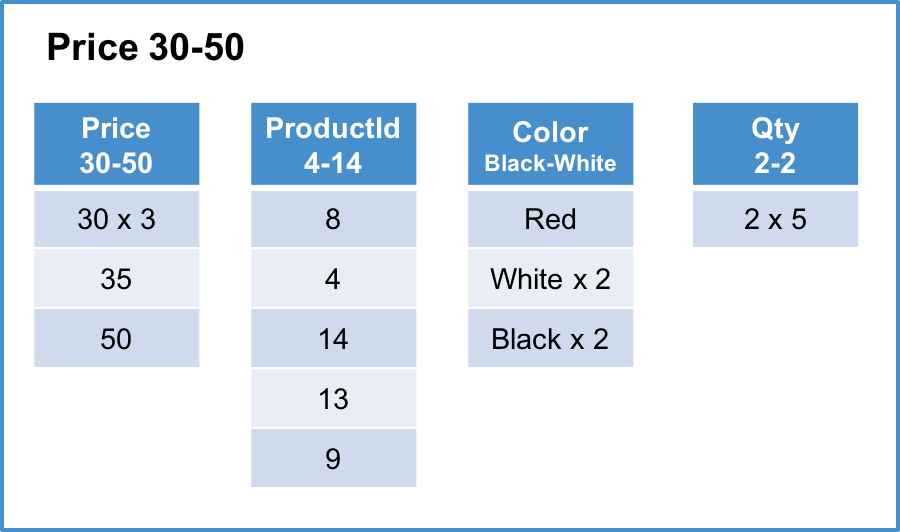
“x N” indicates that the value is repeated N times.
Creating Efficient Columnstore Queries
Queries against tables with a columnstore index in SingleStore can take advantage of five characteristics of a columnstore index:
- All queries will be able to take advantage of the fact that only the column segments containing columns referenced in the query will need to be scanned, as well as the fact that the columnstore’s compression causes less data to need to be scanned. Taking the above table as an example. The query
SELECT SUM(Qty) FROM Products;will only need to scan the threeQtycolumn segments, each of which only contain a single value due to the compression. - Some queries can be performed simply by reading the in-memory metadata for column segments referenced in the query. As an example, the query
SELECT COUNT(*) FROM Products;will only need to read the row count and delete bitmask for all row segments to produce its result, completely eliminating the need to read column segments from disk. Queries that use theMINorMAXaggregates can eliminate the need to read column segments from disk if no delete has been performed against the column segment. - Some queries can reduce the number of segments that need to be read from disk by eliminating these segments based on the segment metadata (min and max values for the segment). The efficiency of this method depends on what percentage of segments can actually be eliminated.
- For queries that filter on the key columns of the columnstore index, segment elimination is typically very efficient as segments within each row segment will not cover overlapping value ranges. For example, in the above table the query
SELECT AVG(Price), AVG(Qty) FROM Products WHERE Price BETWEEN 1 AND 10;will eliminate all segments exceptrow segment: #1 column segment: Price 4-15androw segment: #1 column segment: Qty 2-2which will be scanned. - For queries that filter on the non-key columns that don’t correlate with the key columns, segment elimination can be much less valuable as segments within each row segment can cover overlapping value ranges. For example, in the above table, the query
SELECT AVG(Price) FROM Products WHERE Color = 'Red';will be forced to scan all segments for thePriceandColorcolumns as no segment can be eliminated when the valueRedis contained in all segments of theColorcolumn.
- For queries that filter on the key columns of the columnstore index, segment elimination is typically very efficient as segments within each row segment will not cover overlapping value ranges. For example, in the above table the query
- Queries that join tables on columns that are the index columns of a columnstore index can be performed very efficiently through the use of a merge join algorithm allowing the join to be performed by simply scanning two segments that need to be joined in lock-step.
- Certain types of data allow filters and group-by operations to be performed without decompressing data from its serialized-for-disk format. This greatly improves performance by reducing the amount of data that need to be processed, especially when the cardinalities of the involved columns are low. This optimization is only performed in cases when execution run time would be improved. See Understanding Operations on Encoded Data for more information.
- Queries with selective filters use subsegment access. These queries seek into column segments to read the needed values, rather than scanning whole segments. For a columnstore table
MyTable, the querySELECT Field1, Field2 FROM MyTable WHERE Field1 > 50uses subsegment access. Selective filters with multiple conditions, such asSELECT Field1, Field2 FROM MyTable WHERE Field1 > 50 AND Field2 > 100, also use subsegment access. - Queries using equality filters can take advantage of hash indexes. See an example. The previous note applies to these queries, since equality filters are often selective filters.

