You are viewing an older version of this section. View current production version.
Cluster Components
Key Components
The following components are fundamental to a cluster. They are also key terms that are used throughout the documentation.
Cluster
A cluster encompasses all of the nodes that are included in a complete SingleStore DB installation. A cluster contains aggregator nodes and leaf nodes.
Node
A node is a server that has an installation of an SingleStore DB instance.
Leaf
A leaf is a node that stores a subset of a cluster’s data. A cluster typically contains many leaves.
Partition
A partition contains a subset (a shard) of a database’s data. A leaf contains multiple partitions. When you run CREATE DATABASE, SingleStore DB splits the database into partitions, which are distributed evenly among available leaves. With CREATE DATABASE, you can specify the number of partitions with the PARTITIONS=X option. If you don’t specify the number of partitions explicitly, the default is used (the number of leaves times the value of the default_partitions_per_leaf engine variable.
Types of Tables
A distributed table’s data is distributed across partitions. By contrast, a reference table’s data is replicated, in full, to all nodes in a cluster.
A temporary table is distributed, but is not persisted.
Aggregator
An aggregator is a node that routes queries to the leaves, aggregates intermediate the results, and sends the results back to the client. There are two types of aggregators: master and child. A cluster contains exactly one master aggregator and may contain zero or more child aggregators (depending on query volume).
Master Aggregator
A master aggregator is a specialized aggregator responsible for cluster monitoring and failover.
Except for DDL operations and writes to reference tables, which must go through the master aggregator, any query can be run against any aggregator.
Aggregator to Leaf Ratio
The minimal setup for a cluster is just one aggregator (the master aggregator) and one leaf. You can add more aggregators, which will read metadata from the master aggregator, and can run DML commands on the leaves.
The number of deployed aggregator and leaf nodes determines the storage size and performance of a cluster. Typical deployments have a 5:1 ratio of leaf:aggregator nodes. In a well-designed cluster:
- Applications that require higher connection capabilities from application servers have a higher aggregator-to-leaf node ratio.
- Applications with larger storage requirements have a higher leaf-to-aggregator node ratio.
Interaction of Cluster Components
You run database queries against an aggregator. Most of the communication between aggregators and leaves for query execution is also implemented as SQL statements.
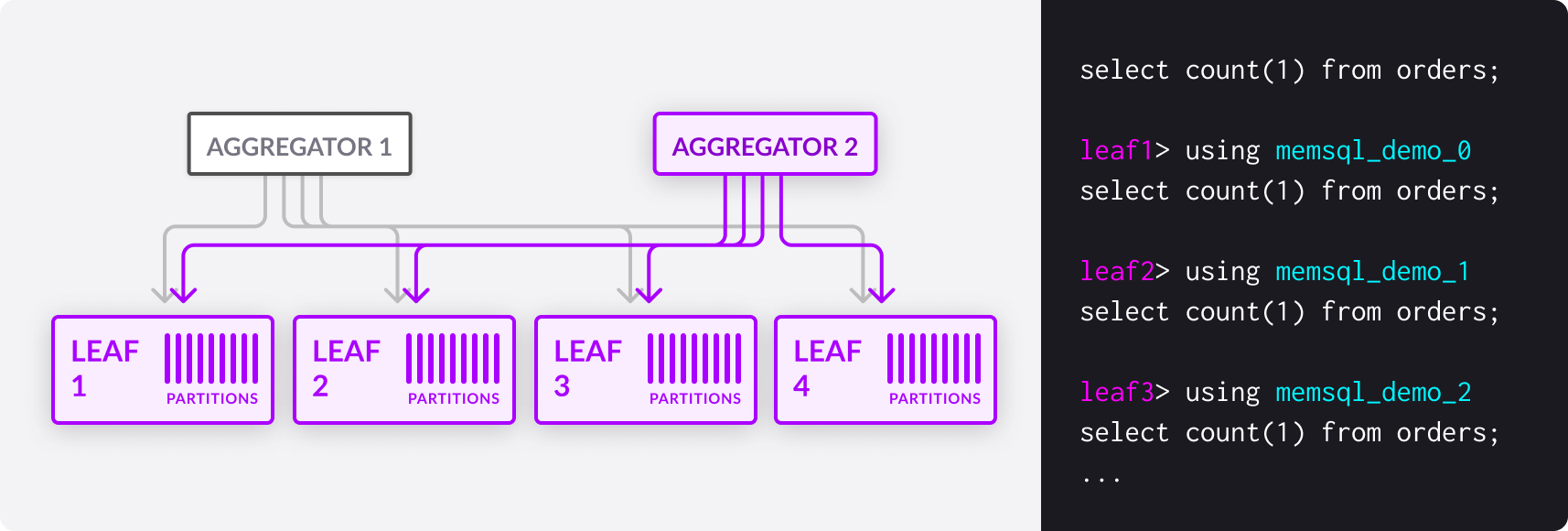
Parallel Execution of Queries
By default, SingleStore DB will create one partition per CPU core on the leaves for maximum parallelism. This number is configurable cluster-wide with the default-partitions-per-leaf variable, or as an optional parameter to CREATE DATABASE.
In the context of query execution, a partition is the granular unit of query parallelism. In other words, every parallel query is run with a level of parallelism equal to the number of partitions. You can view the partitions in a database with SHOW PARTITIONS.

