This guide will show you how to load data into your cluster using SingleStore Pipelines. Pipelines is a powerful feature that can extract, transform, and load external data without the need for third-party tools or middleware. This guide will show you how to load the TPC-H dataset and then query it to get business-critical metrics.
Before You Begin
- You need a SingleStore Managed Service cluster or a self-managed cluster running on Amazon Web Services. See the Deploy SingleStore DB for more details.
What is TPC-H?
The TPC Benchmark™H (TPC-H) is a decision support benchmark. It consists of a suite of business oriented ad-hoc queries and concurrent data modifications. The queries and the data populating the database have been chosen to have broad industry-wide relevance. This benchmark illustrates decision support systems that examine large volumes of data, execute queries with a high degree of complexity, and give answers to critical business questions.
Create the Database
-
Navigate to the SQL Editor in SingleStore DB Studio.
-
Copy the following queries into the SQL Editor by clicking the copy icon in the code block.
WarningAfter you pasted the query into SQL Editor, select all queries before clicking Run.
The following queries will create eight tables associated with business data.
DROP DATABASE IF EXISTS tpch; CREATE DATABASE tpch; USE tpch; CREATE TABLE `customer` ( `c_custkey` int(11) NOT NULL, `c_name` varchar(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `c_address` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `c_nationkey` int(11) NOT NULL, `c_phone` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `c_acctbal` decimal(15,2) NOT NULL, `c_mktsegment` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `c_comment` varchar(117) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`c_custkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `lineitem` ( `l_orderkey` bigint(11) NOT NULL, `l_partkey` int(11) NOT NULL, `l_suppkey` int(11) NOT NULL, `l_linenumber` int(11) NOT NULL, `l_quantity` decimal(15,2) NOT NULL, `l_extendedprice` decimal(15,2) NOT NULL, `l_discount` decimal(15,2) NOT NULL, `l_tax` decimal(15,2) NOT NULL, `l_returnflag` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `l_linestatus` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `l_shipdate` date NOT NULL, `l_commitdate` date NOT NULL, `l_receiptdate` date NOT NULL, `l_shipinstruct` char(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `l_shipmode` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `l_comment` varchar(44) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`l_orderkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `nation` ( `n_nationkey` int(11) NOT NULL, `n_name` char(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `n_regionkey` int(11) NOT NULL, `n_comment` varchar(152) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`n_nationkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `orders` ( `o_orderkey` bigint(11) NOT NULL, `o_custkey` int(11) NOT NULL, `o_orderstatus` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_totalprice` decimal(15,2) NOT NULL, `o_orderdate` date NOT NULL, `o_orderpriority` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_clerk` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `o_shippriority` int(11) NOT NULL, `o_comment` varchar(79) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`o_orderkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `part` ( `p_partkey` int(11) NOT NULL, `p_name` varchar(55) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `p_mfgr` char(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `p_brand` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `p_type` varchar(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `p_size` int(11) NOT NULL, `p_container` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `p_retailprice` decimal(15,2) NOT NULL, `p_comment` varchar(23) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`p_partkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `partsupp` ( `ps_partkey` int(11) NOT NULL, `ps_suppkey` int(11) NOT NULL, `ps_availqty` int(11) NOT NULL, `ps_supplycost` decimal(15,2) NOT NULL, `ps_comment` varchar(199) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY(`ps_partkey`), KEY (`ps_partkey`,`ps_suppkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `region` ( `r_regionkey` int(11) NOT NULL, `r_name` char(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `r_comment` varchar(152) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`r_regionkey`) USING CLUSTERED COLUMNSTORE ); CREATE TABLE `supplier` ( `s_suppkey` int(11) NOT NULL, `s_name` char(25) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `s_address` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `s_nationkey` int(11) NOT NULL, `s_phone` char(15) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `s_acctbal` decimal(15,2) NOT NULL, `s_comment` varchar(101) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, SHARD KEY (`s_suppkey`) USING CLUSTERED COLUMNSTORE ); -
In the SQL Editor, select all of the queries. On Mac OS X, use ⌘ + A. On Windows, Ctrl + A.
-
Click Run.
-
Your tables are all setup if you see Success on all queries.
Load Data with Pipelines
This part of the guide will show you how to pull the TPC-H data from a public S3 bucket into your SingleStore DB database using Pipelines. Because of the powerful Pipelines functionality, loading TPC-H SF100 (approximately 100 GBs of row files) will take around four minutes on your cluster in AWS. Once a pipeline has been created, SingleStore DB will continuously pull data from the bucket.
-
Create the pipelines by copying the following block. Again, make sure you select all the queries in SQL Editor before clicking Run.
use tpch; CREATE OR REPLACE PIPELINE tpch_100_lineitem AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/lineitem/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE lineitem FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_customer AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/customer/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE customer FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_nation AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/nation/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE nation FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_orders AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/orders/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE orders FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_part AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/part/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE part FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_partsupp AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/partsupp/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE partsupp FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_region AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/region/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE region FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n'; CREATE OR REPLACE PIPELINE tpch_100_supplier AS LOAD DATA S3 'memsql-tpch-dataset/sf_100/supplier/' config '{"region":"us-east-1"}' SKIP DUPLICATE KEY ERRORS INTO TABLE supplier FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n';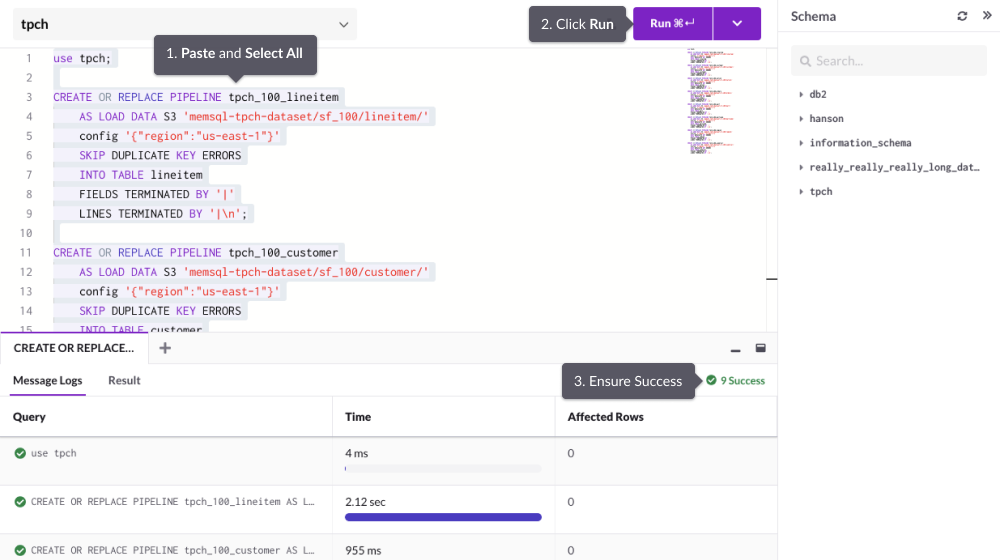
-
Start the pipelines by running the following queries.
use tpch; START ALL PIPELINES;Once you see Success messages for all the Pipelines created, SingleStore DB will begin pulling data from the S3 datasource.
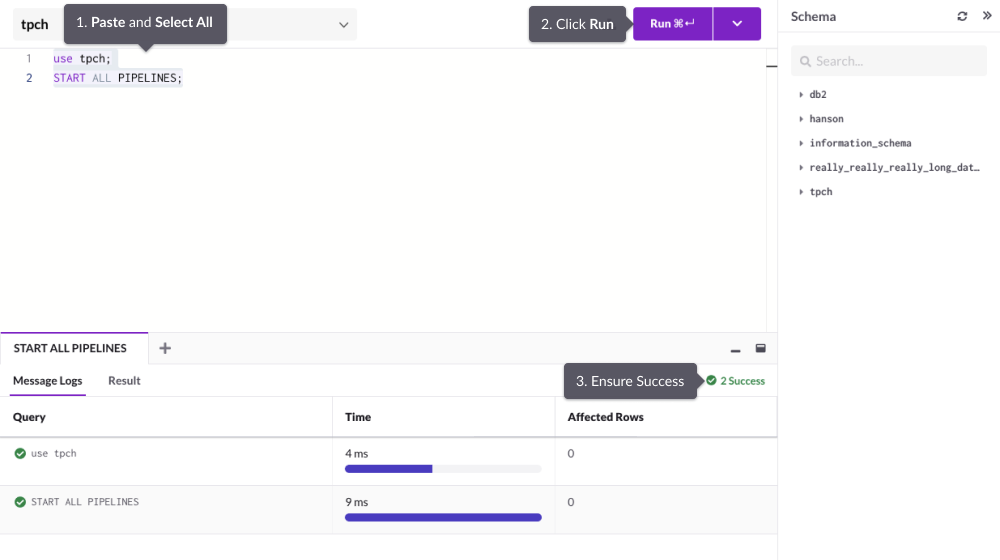
The SQL Editor only runs the queries you have selected, so make sure you have them all selected before clicking Run.
Verify Pipeline Success
First, navigate to Pipelines within Studio. This is where you can see the status of each pipeline job.
The entire loading process takes around four minutes, but you do not need to wait for Pipelines to finish before querying. You can query the data as soon as you have started the loading process; this is part of the powerful functionality of Pipelines.
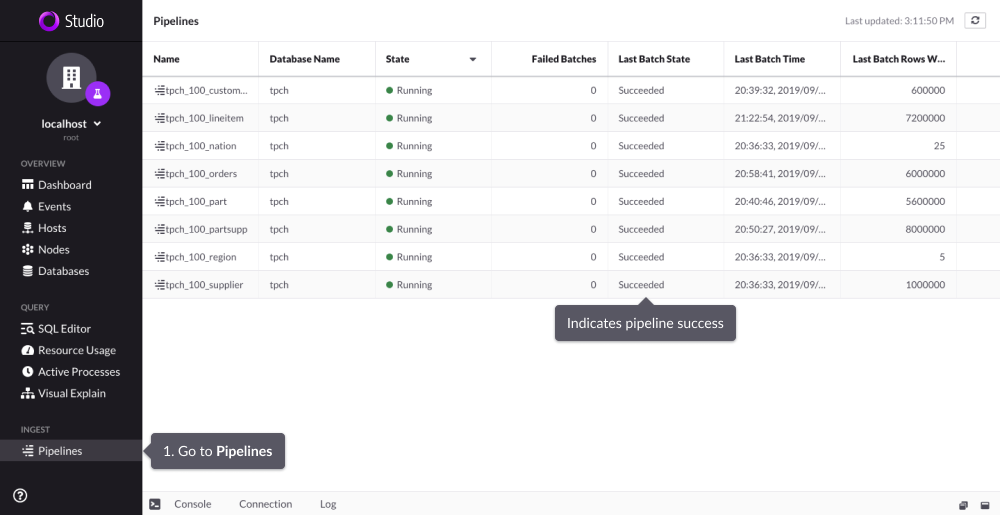
In the next page, we will show you how to get business-critical metrics.

