You are viewing an older version of this section. View current production version.
Kafka Pipelines Overview
MemSQL Pipelines can extract data from Apache Kafka. Kafka and MemSQL share a similar distributed architecture that makes Kafka an ideal data source for Pipelines. To understand Kafka’s core concepts and how it works, please read the Kafka documentation. This section assumes that you understand Kafka’s basic concepts and terminology.
Example Kafka Pipeline Scenario
The easiest way to understand a Kafka pipeline is by considering an example scenario.
Imagine you have a small Kafka cluster with two brokers: one broker is a leader and one broker is a follower. There are four partitions spread across the brokers.
You also have a small MemSQL Database cluster with one master aggregator node, one child aggregator node, and two leaf nodes. There are four partitions spread across the leaf nodes. If you’re not familiar with MemSQL’s cluster architecture, this arrangement of nodes and partitions is common.
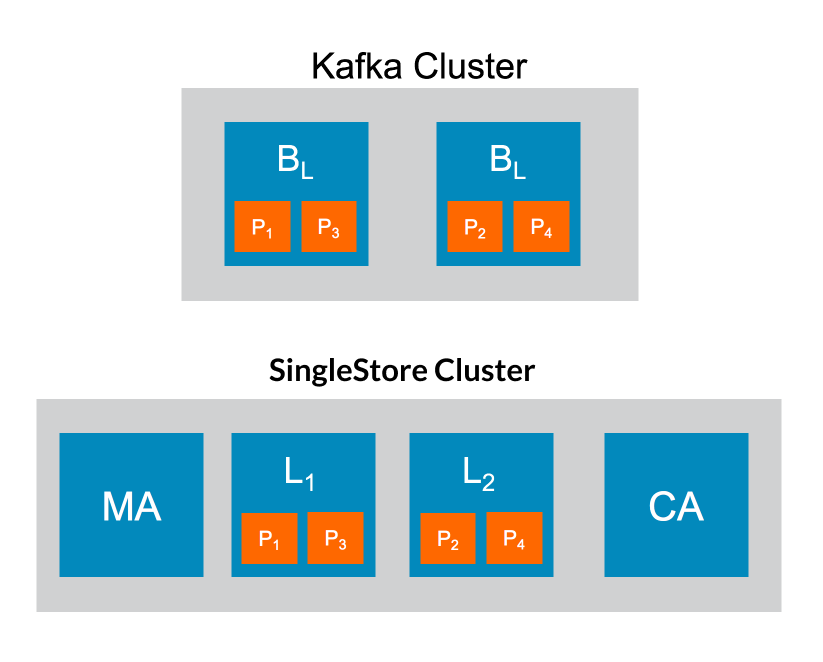
Given this topology, the following steps occur when you start a Kafka pipeline:
- The MemSQL cluster’s master aggregator connects to the Kafka lead broker and requests metadata about the Kafka cluster. This metadata includes information about the Kafka cluster’s brokers, topics, and partitions.
- The master aggregator parses the metadata and learns that there are four partitions spread across two Kafka brokers. The master aggregator decides how to process Kafka topics, which are groups of partitions.
- The master aggregator assigns leaf node partitions to Kafka partitions and sets the leaf nodes’ configuration. One important configuration detail is the maximum number of offsets to read per batch. Once configured, each leaf node in the cluster effectively becomes a Kafka consumer. At a lower level, each partition in a leaf node is paired with a partition in a Kafka broker.
- Once a leaf node’s partitions have been paired with Kafka partitions, each leaf node in the cluster begins extracting data directly from the Kafka brokers. The leaf nodes individually manage which message offsets have been read from a given Kafka partition.
- Offsets are ingested in batches, and the maximum number per batch is specified in the engine variables. When an extracted batch has successfully read its offset data, the batch is then optionally transformed and finally loaded into the destination table.

