You are viewing an older version of this section. View current production version.
S3 Pipelines Quickstart
S3 Pipeline Quickstart
To create and interact with an S3 Pipeline quickly, follow the instructions in this section.
Prerequisites
To complete this Quickstart, your environment must meet the following prerequisites:
- Operating System: Mac OS X or Linux
- Docker: Version 1.12 or newer. If using Mac OS X, these instructions are written for Docker for Mac. Docker Toolbox is compatible as well, but no instructions are provided. While Docker is required for this Quickstart, Pipelines and MemSQL itself have no dependency on Docker.
- AWS Account: This Quickstart uses Amazon S3 and requires an AWS account’s access key id and secret access key.
Part 1: Creating an Amazon S3 Bucket and Adding a File
The first part of this Quickstart involves creating a new bucket in your Amazon S3 account, and then adding a simple file into the bucket. You can create a new bucket using a few different methods, but the following steps use the browser-based AWS Management Console.
Note: The following steps assume that you have previous experience with Amazon S3. If you are unfamiliar with this service, see the Amazon S3 documentation.
- On your local machine, create a text file with the following CSV contents and name it books.txt:
The Catcher in the Rye, J.D. Salinger, 1945
Pride and Prejudice, Jane Austen, 1813
Of Mice and Men, John Steinbeck, 1937
Frankenstein, Mary Shelley, 1818
-
In a browser window, go to https://console.aws.amazon.com and authenticate with your AWS credentials.
-
After you’ve authenticated, go to https://console.aws.amazon.com/s3 to access the S3 console.
-
From the S3 console, click Create Bucket in the top left of the page.
-
From the Create a Bucket dialog, enter the name of the bucket and select an AWS region.
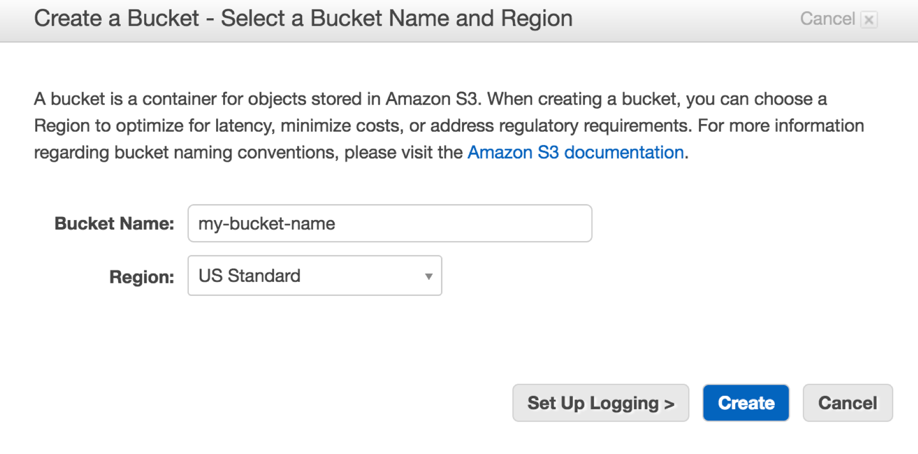 Take note of the Region where the bucket will be created. You can specify
Take note of the Region where the bucket will be created. You can specify CONFIGclause when creating a pipeline to provide the bucket’s region, but if noCONFIGclause is specified, the pipeline will be automatically configured to use theus-east-1region. -
After the bucket has been created, click on it from the list of buckets.
-
Now you will upload the books.txt file you created earlier. Click the Upload button in the top left of the page, and either drag-and-drop the books.txt file or select it using a file dialog by clicking Add Files.
Once the books.txt file has been uploaded, you can proceed to the next part of the Quickstart.
Part 2: Creating a MemSQL Database and S3 Pipeline in Docker
Now that you have an S3 bucket that contains an object (file), you can use MemSQL to create a new pipeline and ingest the messages. In this part of the Quickstart, you will create a Docker container to run MemSQL and then create a new S3 pipeline.
In a new terminal window, execute the following command:
docker run --name memsql -p 3306:3306 -p 9000:9000 memsql/quickstart
This command automatically downloads the memsql/quickstart Docker image from Docker Hub, creates a new container using the image, assigns the container a user-friendly name (memsql), and finally starts the container.
You will see a number of lines outputted to the terminal as the container initializes and MemSQL starts. Once the initialization process is complete, open a new terminal window and execute the following command:
docker exec -it memsql memsql
This command accesses the MemSQL client within the Docker container. Now we will create a new database and a table that adheres to the schema contained in books.txt file. At the MemSQL prompt, execute the following statements:
CREATE DATABASE books;
CREATE TABLE classic_books
(
title VARCHAR(255),
author VARCHAR(255),
date VARCHAR(255)
);
These statements create a new database named books and a new table named classic_books, which has three columns: title, author, and date.
Now that the destination database and table have been created, you can create an S3 pipeline. In Part 1 of this Quickstart, you uploaded the books.txt file to your bucket. To create the pipeline, you will need the following information:
- The name of the bucket, such as:
my-bucket-name - The name of the bucket’s region, such as:
us-west-1 - Your AWS account’s access keys, such as:
- Access Key ID:
your_access_key_id - Secret Access Key:
your_access_key_id
- Access Key ID:
Using these identifiers and keys, execute the following statement, replacing the placeholder values with your own:
CREATE PIPELINE library
AS LOAD DATA S3 'my-bucket-name'
CONFIG '{"region": "us-west-1"}'
CREDENTIALS '{"aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_secret_access_key"}'
INTO TABLE `classic_books`
FIELDS TERMINATED BY ',';
This statement creates a new pipeline named library, but the pipeline has not yet been started. To start it, execute the following statement:
START PIPELINE library;
This statement starts the pipeline. To see whether to the pipeline is running, execute:
SHOW PIPELINES;
If the pipeline is successfully running, you will see the following result:
memsql> SHOW PIPELINES;
+----------------------+---------+
| Pipelines_in_books | State |
+----------------------+---------+
| library | Running |
+----------------------+---------+
1 row in set (0.00 sec)
At this point, the pipeline is running and the contents of the books.txt file should be present in the classic_books table. Execute the following statement:
SELECT * FROM classic_books;
The result of this statement will show the following result:
memsql> SELECT * FROM classic_books;
+------------------------+-----------------+-------+
| title | author | date |
+------------------------+-----------------+-------+
| The Catcher in the Rye | J.D. Salinger | 1945 |
| Pride and Prejudice | Jane Austen | 1813 |
| Of Mice and Men | John Steinbeck | 1937 |
| Frankenstein | Mary Shelley | 1818 |
+------------------------+-----------------+-------+
4 rows in set (0.13 sec)
Next Steps
Now that you have a running pipeline, any new files you add to your bucket will be automatically ingested. To understand how an S3 pipeline ingests large amounts of objects in a bucket, see the Parallelized Data Loading section in the Extractors topic. You can also learn more about how to transform the ingested data by reading the Transforms topic.

