This topic is a reference for database engineers on how to optimize table data structures for MemSQL. This document assumes the reader is familiar with the following concepts:
- How to connect to MemSQL
- Creating tables and running queries in a SQL database
- Why you would add an index to a table
- Aggregators and leaves
This topic is comprised of the following sections:
- Key Considerations for Understanding Your Workload
- Rowstore vs. Columnstore
- Shard Keys
- Choosing Rowstore Keys
- Choosing a Columnstore Key
Key Considerations for Understanding Your Workload
Before attempting any schema design, it is critical to understand the nature of the workload. Ask yourself the following questions before getting started:
- Is data loaded in trickles, large batches, or concurrent inserts? Is data frequently updated?
- Is data ingest speed more important than query performance?
- Are the queries mostly working with a small subset of rows related to the entire dataset (probably 0.1% or less)? Are the queries dealing with the entire dataset or a big subset of the data?
- Which tables do you tend to join and what columns do you use to join them?
- What columns do you tend to use in filters?
Rowstore vs. Columnstore
The most important consideration when creating a table is its data layout. MemSQL supports two types of tables: in-memory rowstores and on-disk columnstores.
Rowstore tables are good for seeks and concurrent updates. They keep all the data in memory and all the columns for a given row together, resulting in very fast performance when running queries that seek to specific rows. With rowstore, data is stored in lock-free indexes for great performance at high concurrency. Rowstore tables can use multiple indexes, allowing them to flexibly support many types of queries. Transactional style OLTP workloads with frequent updates are a good fit for rowstore tables.
Columnstore tables are good for sequential scans. Data is stored on disk by column, resulting in good data compression and exceptional performance when running queries that perform sequential scans and touch relatively few columns. Since columnstore tables can only have a single index (the columnstore key used to sort each segment), they are less versatile than rowstore tables.
In general, columnstore tables are effective when your workload matches the following descriptions as much as possible:
- A large number of rows are scanned sequentially (i.e. millions of rows or >5% of the table)
- Aggregation happens over only a few columns (e.g. <10 columns)
- Small updates and deletes are rare; most affect large batches of rows
Columnstore tables should be considered for environments where the data is updated infrequently, and most updates are large bulk updates. Frequent single row transactional style updates do not perform well with columnstore tables.
Choosing a Table’s Data Layout
The following questions are quick guides you can ask yourself to determine whether rowstore or columnstore is right for your data:
- Do you need to enforce unique constraints on your data? Use a rowstore and set an appropriate primary key.
- Do you have many different queries that selectively filter on different columns? Use a rowstore and use multiple indexes.
- Do you seek to points in your data? Use a rowstore for point queries.
- Do you need to support high concurrency updates or deletes? Use a rowstore to benefit from the lock free data structures.
- Do you only aggregate a large amount of data that you only update or delete in bulk? Use a columnstore for fast performance.
In addition to these questions, refer to the following resources for more information:
Check Your Understanding:
Q: Do rowstore tables ever write to disk?
A: Yes – data in a rowstore is also written to the transaction log on disk so that it can be recovered when MemSQL is restarted.
Q: Do columnstore tables use memory?
A: Absolutely – MemSQL uses the operating system disk buffer cache to cache segment files in memory. Good performance in columnstore can only be achieved when there is enough memory to cache the working set. In addition, columnstore tables use a rowstore buffer table as a special segment to batch writes to the disk.
Q: What if I need small high concurrency updates and my data doesn’t fit in memory?
A: This workload is best for a rowstore; we strongly recommend you get more memory or change your data retention policy so that it fits in memory.
Q: Are rowstore tables always faster than columnstore tables?
A: No, columnstore tables are faster on some workloads – if the workload is batch inserts and sequential reads (e.g. an analytical workload with lots of scans) a columnstore can be significantly faster.
Shard Keys
The second consideration when putting data into MemSQL is choosing the shard key for a table. Data is distributed across the MemSQL cluster into a number of partitions on the leaf nodes. The shard key is a collection of the columns in a table that are used to control how the rows of that table are distributed. To determine the partition responsible for a given row, MemSQL computes a hash from all the columns in the shard key to the partition ID. Therefore, rows with the same shard key will reside on the same partition.
For example, the table below has the shard key that contains only the first column. All people with the same first name will be stored on the same partition.
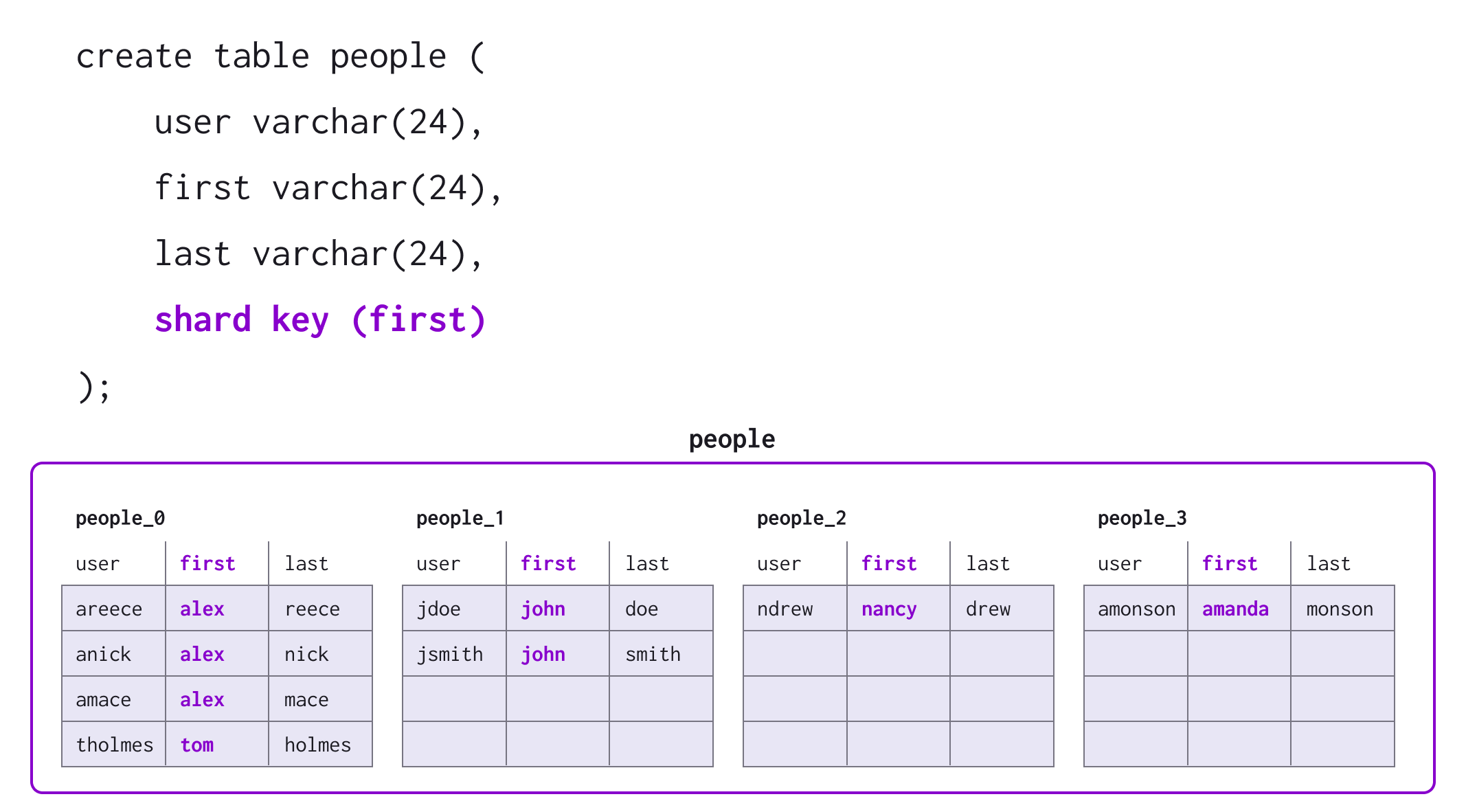
Check Your Understanding
Q: Why are there restrictions on ALTERing or UPDATEing the shard key of a table?
A: Unlike adding a new index to a rowstore table (which only requires adding information to existing data without moving it), ALTERing the shard key requires moving the table to different partitions. Similarly, UPDATEing a column in the shard key could require a row to be moved to a different partition.
Q: Why is the shard key required to be a subset of the primary key for a rowstore table?
A: The primary key of a rowstore table requires that there are no duplicate rows. We can only enforce uniqueness by ensuring that all potentially duplicate data is on the same partition.
Choosing a Shard Key
Shard keys are specified at the time of CREATE TABLE. Once created, the shard key for a table cannot be modified. There are two competing considerations when sharding data:
- Distributing data evenly across partitions
- Partitioning data on columns you frequently filter or join
First, distributing data evenly makes capacity planning much easier since the system will use its resources uniformly. Query performance can also suffer when the data is skewed or unevenly distributed, because there can be slow partitions. Multi-partition queries cannot run faster than the slowest partition involved.
Second, queries perform significantly better and use fewer resources when the optimizer can precisely understand what partitions are used. MemSQL only has to involve a single partition if the query filter matches the shard key, which greatly reduces cluster resource usage for high concurrency workloads. Similarly, joins of multiple tables that have the same shard key will be performed locally on the leaf partition rather than redistributing the data around the cluster, resulting in much faster joins that can be done at significantly higher concurrency. Joins of tables with different shard keys, or distributed joins, are substantially slower and more resource-intensive.
For example, the following query is considered “single partition” because the filter clause (where first = ‘john') includes the columns of the shard key. The aggregator only needs to talk to one partition to get the data:

These two concerns typically run into conflict when the data is skewed. For example, first is probably a poor shard key in the table above, because some first names are much more common than others. In cases like these, it is generally more important that the data be evenly distributed so that the cluster does not run out of capacity. user is probably a better choice of shard key since it will be more evenly distributed and it is likely to be a filter for queries against the table. If you want a table to get truly uniform sharding, you may also shard on an auto-increment column.
In addition to specifying a key the system will use to shard the table, you may also distribute data as follows:
- Keyless sharding is the default for tables with no primary key and no explicit shard key. You can explicitly declare a table as keyless sharded by specifying a shard key with an empty list of columns:
shard key () ...With keyless sharding, data is distributed uniformly across partitions in most cases. Cases when the data becomes non uniform typically occur becauseINSERT … SELECTstatements are optimized to insert locally into the same partition. This makes these operations substantially faster, but it does mean that they can cause skew where there wasn’t before or amplify existing skew. To remove skew in these cases, you can force theINSERT … SELECTto redistribute the data with theforce_random_reshufflequery hint. See more about this in the INSERT reference topic. Keyless sharding also makes it impossible to do single partition queries or local (collocated) joins, because rows are not associated with specific partitions via an explicit key value. The following are examples ofCREATE TABLEstatements which will cause keyless sharding to be used.
CREATE TABLE t1(a INT, b INT);
CREATE TABLE t1(a INT, b INT, SHARD KEY());
- Data in reference tables is duplicated on every node in the cluster, including aggregators. This makes it possible to do local joins between reference tables and any other tables; however, the table consumes a large amount of cluster storage because a copy of the entire table is stored on every node. Furthermore, reference tables replicate synchronously to the aggregators and asynchronously to the leaves, dramatically limiting the performance of writes. For star schema workloads, reference tables are ideal for small, slowly changing dimension tables.
Questions to Ask When Choosing a Shard Key
- Does this table have a primary key? Make sure there is a shard key and that it is a subset of the primary key.
- Do you frequently join on a specific set of columns (e.g.
where users.id = action.user_id and users.country = action.country)? Try to make the shard key a subset of the joined columns. - Do you frequently filter on a specific set of columns (e.g.
where user_id = 17 and date = '2007-06-14')? Try to make the shard key a subset of the filtered columns. - Do you have high concurrency queries? Choose a shard key that allows these queries to be single partition.
- Is your data skewed for your current choice of shard key? Try to add additional columns to the shard key to ensure even distribution.
- Do you need to
UPDATEorALTERany fields in the shard key? Remove those fields from the shard key. - Is this a small, infrequently changing table that needs to be on every node in the cluster to guarantee local joins? Use a reference table instead of sharding the table.
In addition to these questions, see the Data Skew topic for more information.
Check Your Understanding
Q: Why can the MemSQL Spark Connector load data directly into the leaf partitions for keyless sharding only?
A: If there is keyless sharding, data can be placed anywhere in the cluster. Since the leaf partitions are fully functional databases, the spark connector can connect directly to load the data in parallel. If a shard key is used, the connector must use an aggregator to ensure that data is inserted into the correct partition.
Q: Why does MemSQL use the primary key as a shard key if there is no explicit shard key?
A: It is very common to query tables with a filter on the primary key; in addition, the uniqueness constraint of primary keys guarantees that data will not be skewed.
Q: Why is it generally better to use a shard key with the fewest number of columns, as long as it’s not skewed?
A: We can only optimize queries to run against a single partition when they filter or join on the entire shard key. A smaller shard key is likely to match more queries.
Q: Why is it faster to run queries that group by the shard key?
A: When the grouping matches the shard key, queries are faster because the GROUP BY can be executed locally on each partition. This effect is much more pronounced when the groups are high-cardinality.
Choosing Rowstore Keys
You may define indexes, also called keys, on MemSQL rowstore tables. MemSQL uses these keys to efficiently find specific rows.
There are two storage types for rowstore indexes: a lockfree skiplist and a lockfree hash table. In both cases, we use lockfree data structures to optimize the performance of concurrent updates to the table.
- By default, indexes are stored as skiplists, which have similar functional and performance characteristics as B-trees in other databases. A skiplist is a data structure optimized for ordered data that stores rows in collections of increasingly smaller ordered lists. Queries can quickly seek data by binary searching using the different sized lists and can quickly scan over ranges of data by iterating over the largest list. For multi-column indexes, query filters must match a prefix of the index column list to be able to take advantage of the index.
- A hash table is a data structure optimized for fast lookups, which stores rows in a sparse array of buckets indexed by a hash function on the relevant columns. Queries can quickly find exact match data by examining only the bucket identified by the hash function, but cannot easily scan over a subset of the table. For multi-column indexes, query filters must match all of the index columns to be able to take advantage of the index. Due to this inflexibility, we discourage the use of hash indexes. They should only be used when there is a demonstrated need and measurable benefit on your particular dataset and workload.
Another consideration when choosing an index is the overhead of adding another index. Each added index uses extra memory for the additional data structures – on average about 40 bytes per row – and slightly slows inserts due to the additional data structures that need to be updated.
Each rowstore table may have at most one primary key and optionally many secondary keys. Scans on the primary key are generally somewhat faster than on secondary keys. For example, if the data was inserted in primary key order, the rows would be in memory order for the primary key and have better cache locality for the primary key than for a secondary key.
For more information, refer to the following two resources:
Check Your Understanding
Q: For the table, CREATE TABLE t(a INT, b INT, KEY (a, b)), will the query SELECT SUM(a) FROM t WHERE b = 3 benefit from the index?
A: No, since the only column in the filter list, b, is not a prefix of the key (a, b), the query cannot benefit from the index. The query SELECT SUM(a) FROM t WHERE a = 3 would be able to benefit from the index since a is a prefix of the key (a, b).
Choosing a Columnstore Key
Columnstore tables have exactly one index, the clustered columnstore sort key. Columnstores partition all rows using this sort key into logical segments, which contain data for many rows. Data within a segment is stored on disk into segment files containing the same field for many rows. This enables two important capabilities. One is to scan each column individually; in essence, being able to scan only the columns that are needed to execute a query with a high degree of locality. The other capability is that columnstores lend themselves well to compression; for example, repeating and similar values can be easily compressed together.
In addition, MemSQL stores metadata for each row segment in memory, which includes the minimum and maximum values for each column contained within the segment. This metadata is used at query execution time to determine whether a segment can possibly match a filter, a process known as segment elimination.
For example, we will use this columnstore table:
CREATE TABLE products (
ProductId INT,
Color VARCHAR(10),
Price INT,
Quantity INT,
KEY (`Price`) USING CLUSTERED COLUMNSTORE
);
The following table represents a logical arrangement of the data in a single partition of the database:
| ProductId | Color | Price | Quantity |
|---|---|---|---|
| 1 | Red | 10 | 2 |
| 2 | Red | 20 | 2 |
| 3 | Black | 20 | 2 |
| 4 | White | 30 | 2 |
| 5 | Red | 20 | 2 |
| 6 | Black | 10 | 2 |
| 7 | White | 25 | 2 |
| 8 | Red | 30 | 2 |
| 9 | Black | 50 | 2 |
| 10 | White | 15 | 2 |
| 11 | Red | 5 | 2 |
| 12 | Red | 20 | 2 |
| 13 | Black | 35 | 2 |
| 14 | White | 30 | 2 |
| 15 | Red | 4 | 2 |
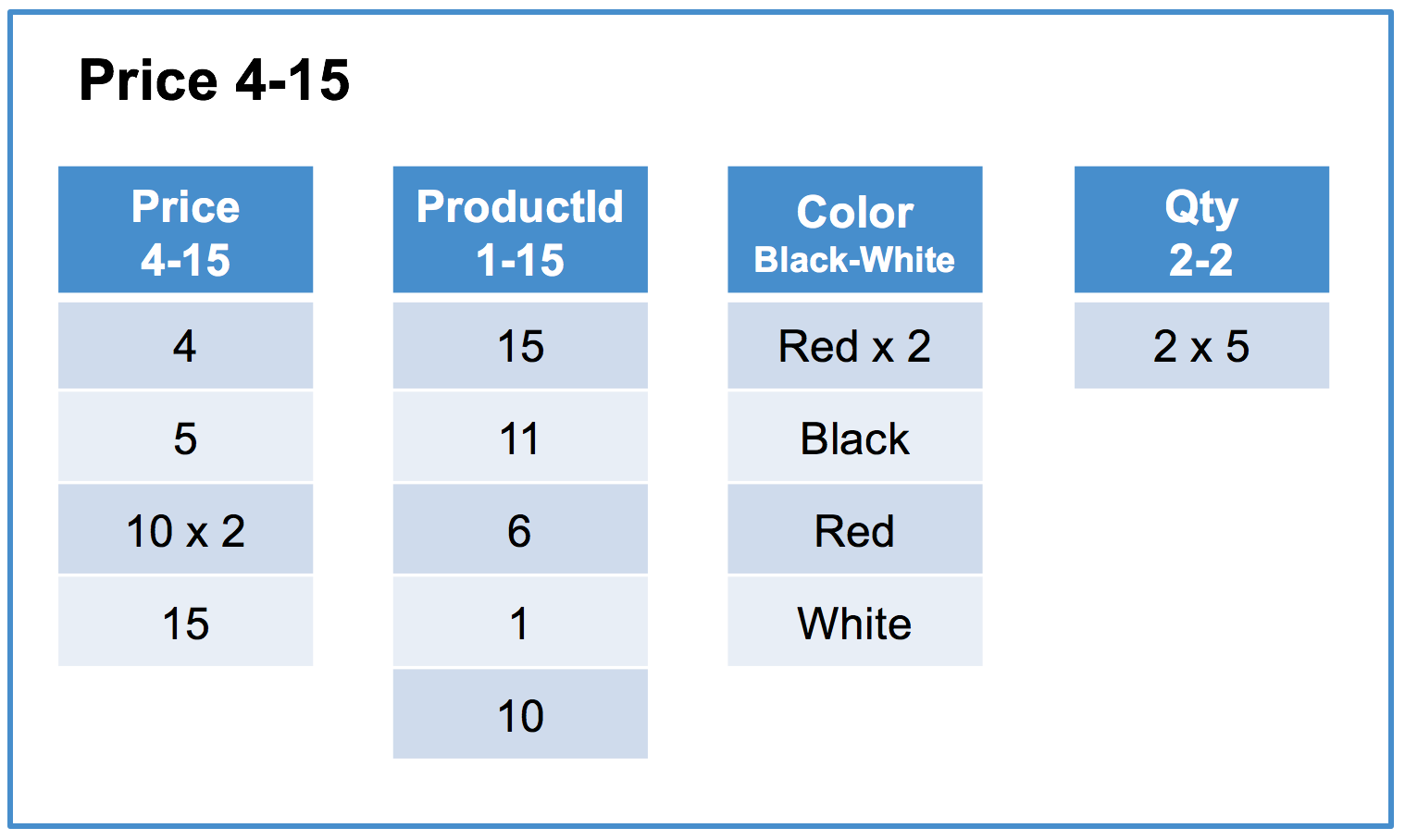
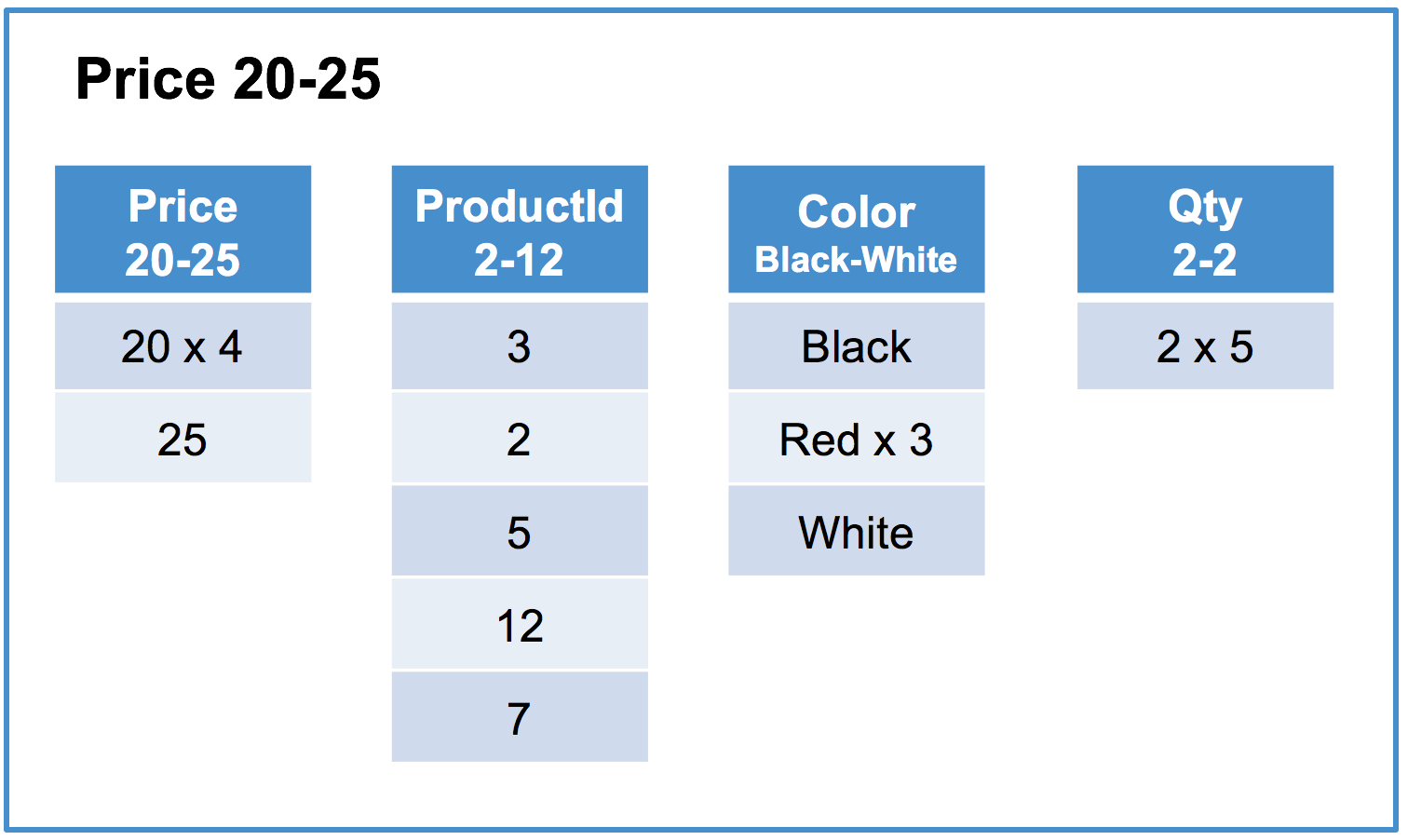
Since this is a columnstore table, the data is split into segments. Column segments typically contain on the order of tens of thousands of rows; in this example, the segment size is 5 rows for readability. In addition, we will use the convention “x N” to indicate that a value is repeated N times.
Row segment #1 of 3:
Row segment #2 of 3:
Row segment #3 of 3:
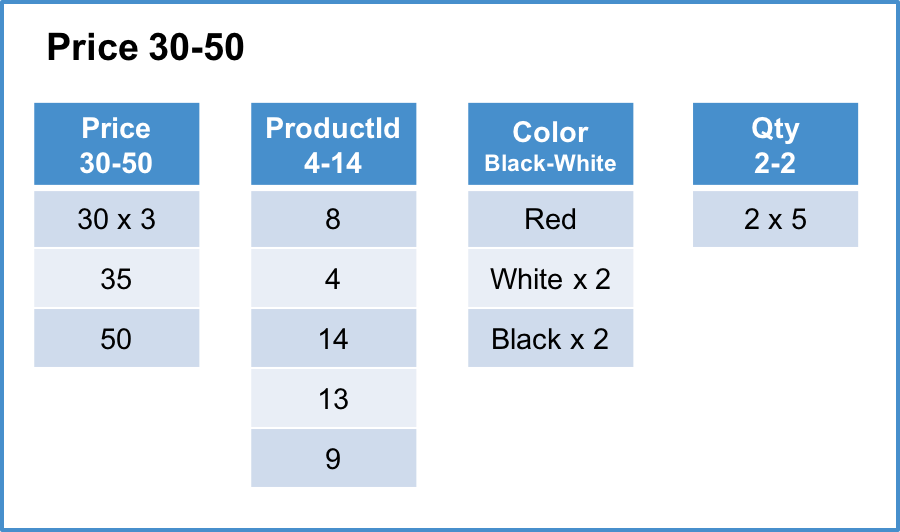
In this example, we can see there are 3 segments containing different ranges of the Price column (4-15, 20-25, and 30-50). Each segment has the same number of rows and is organized data by column. For each column, we store the minimum and maximum values in the segment as metadata.
The single most important consideration for columnstore keys is increasing the amount of segment elimination. The minimum/maximum value metadata is used at query execution time to determine whether a segment can possibly match a filter; if not, the segment is skipped entirely and no data is examined.
A good columnstore key increases the likelihood of this optimization by segmenting data the way it will be filtered. For queries that filter on the key column of the columnstore index, segment elimination is typically very efficient as row segments within each row segment group will not have overlapping segments. For example, in the above table the query SELECT AVG(Price), AVG(Qty) FROM Products WHERE Price BETWEEN 1 AND 10; will eliminate all segments except row segment #1 Price 4-15.
Questions to Ask When Choosing a Columnstore Key:
- Is the data always filtered by some column (e.g. insert timestamp or event type)? Ensure that the common columns for all queries are in the columnstore key to improve segment elimination.
- Is the data generally inserted in order by some column (e.g. insert timestamp)? It’s best to put that column first in the columnstore key to minimize the amount of work required by the background columnstore segment merger.
- Does one column in your key have a higher cardinality than the other? It’s best to put the lowest cardinality columns first to increase the likelihood that segment elimination will be able to affect later columns.
Check Your Understanding
Q: Can the columnstore key and the shard key be different?
A: Absolutely – they are not related at all. It is very common to pick a shard key that matches other rowstore tables (e.g. event_id) to improve join performance and to pick an unrelated columnstore key that matches the common filters on the table (e.g. event_timestamp or event_type).
Q: Is (insert_datetime6, region_id) a good columnstore key?
A: Not necessarily, because the number of distinct microsecond precision timestamps is likely very high. The partitioning of data into segments will likely be entirely controlled by insert_datetime6 and not use region_id. This means that queries scanning microseconds of data will get good segment elimination, because they’ll match fewer segments. However, queries that scan days or months of data would not benefit from segment elimination on region_id. If the data is frequently accessed days or months at a time, it would be better to truncate the precision of the timestamp. For example, use a datetime type or a computed column of DATE_TRUNC('hour', insert_datetime6). In general, your columnstore key should not be more precise than your query filters.
For more information, see the Columnstore topic.

