You are viewing an older version of this section. View current production version.
Connecting from Zoomdata
Zoomdata is the modern business intelligence and data visualization platform for cloud, big data, live streaming data, multi-source, and embedded analytics.
This topic describes how to use Zoomdata to connect to MemSQL to explore data.
The certification matrix below shows the recommended versions for each product or component:
| Certification Matrix | Versions |
|---|---|
| Zoomdata | 3.7.16 |
| MemSQL | 6.8 |
| MySQL JDBC driver | 8.0.13 |
Hardware and Software Requirements
Zoomdata can be downloaded and installed in different Linux distributions. The client application is accessed using web browsers that support web socket technology.
For Linux deployments, a 64-bit Linux-based OS is required. Zoomdata Server also utilizes Java, PostgreSQL and Spark. Ensure that the appropriate version of these tools is used in the deployment of Zoomdata in your operating environment.
For RPM and Ubuntu installations, the following server specifications are recommended:
-
64 GB RAM (minimum is 16 GB)
-
500 GB disk space
-
16 CPU cores
Ports: By default, the Zoomdata Server uses port 8080.
Installation
The installation script (Zoomdata binary) works in the following environments:
-
RHEL/Centos 6 and 7
-
Ubuntu 14.04 and 16.04
The target server for the Zoomdata software should meet the following prerequisites:
-
The server must be connected to the Internet.
-
The server must not have PostgreSQL already installed.
-
The server must not contain any Zoomdata folders or property files from previous versions. If a previous version of Zoomdata was installed on this server, ensure all property files have been deleted before running installer script.
-
The user installing Zoomdata must be able to use the sudo command on the server.
The installation instructions below are based upon the assumption that you are using Ubuntu 16.04 or later:
-
Follow the instructions here to install Zoomdata.
-
Run the following commands to configure the firewall:
sudo apt-get install iptables-persistentsudo iptables -I INPUT 1 -i eth0 -p tcp --dport 8443 -j ACCEPTsudo iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 443 -j DNAT --to-destination :8443sudo iptables -I INPUT 1 -i eth0 -p tcp --dport 80 -j ACCEPTsudo iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to-destination :8080sudo netfilter-persistent savesudo netfilter-persistent reload -
Identify the IP address. To obtain the Zoomdata IP address, enter the following command in a terminal window on the Zoomdata server and an IP will be displayed.
hostname -I
Connection to MemSQL
The Zoomdata MemSQL connector lets you access the data available in MemSQL databases for visualization and exploration using the Zoomdata client.
The MemSQL connector requires a JDBC driver to be configured before you can connect to your data source.
Here are the steps for connecting with MemSQL:
-
Deploy and configure MemSQL cluster. Refer to the Deploy MemSQL guides for help.
-
On your Zoomdata server, download the latest JDBC driver. The supported version is 8.0.13.
-
Place the required driver in the following folder:
/usr/local/share/java/zoomdata. -
Use the following command to access and open the property file:
vi /etc/zoomdata/edc-memsql.properties -
In the
edc-memsql.propertiesfile, add the following properties:datasource.driver-config.jar-path=<JDBC_driver_filepath> datasource.driver-config.class-name=com.mysql.cj.jdbc.Driver -
Save your changes.
-
Restart the corresponding connector by running the command:
sudo systemctl restart zoomdata-edc-memsql -
Open a browser and enter
http://<IP Address>:8080/zoomdata/login. The Zoomdata login screen should appear. Log in as the supervisor, access the Connectors page, and verify that the connector is enabled so it appears in the data source list.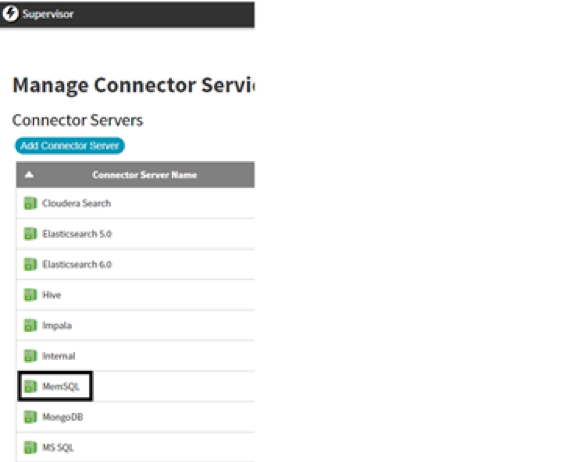
-
Log out and log back in again as
admin.
Query Data from MemSQL
-
Run the Zoomdata Web application through the login page.

-
Once logged in, Click Settings.
-
Click Sources.

-
Click on the MemSQL icon in the Add a New Data Source section.

-
On the General page, provide the name of the source and click Next.

-
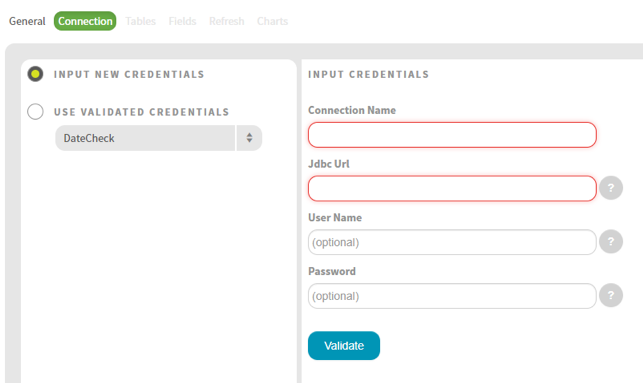
On the Connection page, provide the connection name, JDBC URL, username and password. Click Validate.
-
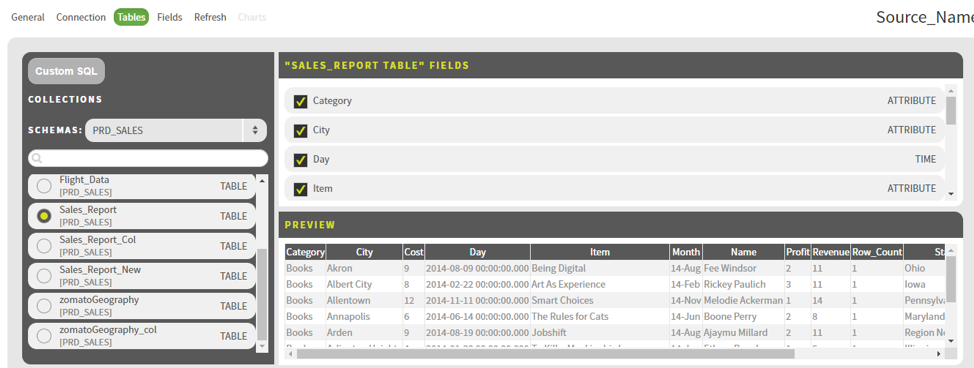
After successful validation, click Next. The Tables page will now be available. In the Tables page, select the schema and the respective table. Click Next.
-
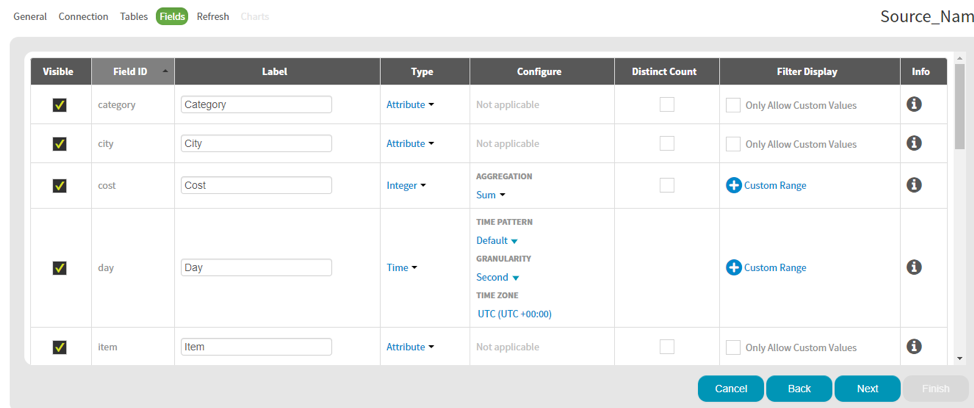
Configure the fields in the Fields page. Click Next.
-
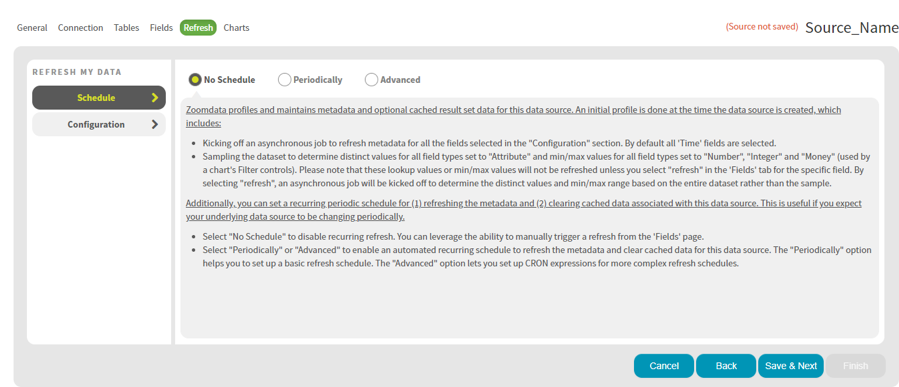
On the Refresh page, configure the scheduling of metadata refresh and cache clearing. Click Save & Next.
-
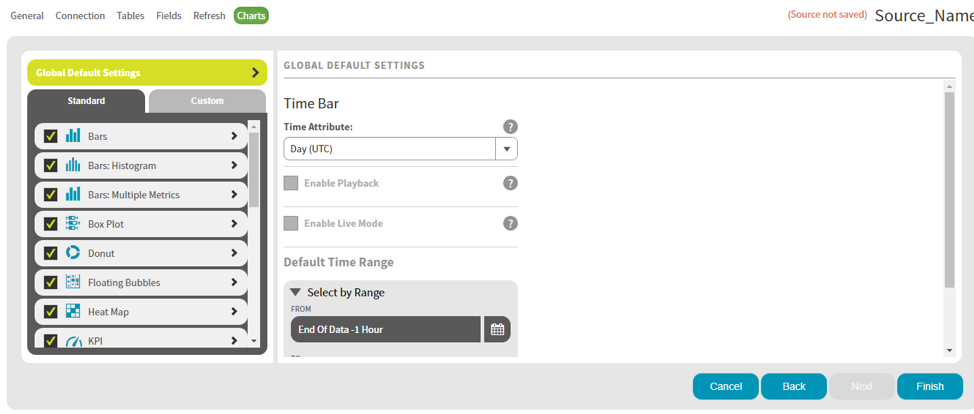
Select the charts for the data source and click Finish.
-
The created data source should be available in the My Data Sources section.

Best practices guide
Follow below strategies to build more efficient Zoomdata dashboards.
Limit the number of visuals in dashboards and reports
- Placing many visuals in a single report slows report performance.
- Limit widget visuals to no more than eight per report page and grids to no more than one per page. Limit pages to no more than 30 points (cards: 1, gauges: 2, charts: 3, maps: 3, grids: 5).
- Limit tiles to no more than 10 per dashboard.
Remove unnecessary interactions between visuals to improve report performance
- By default, all visuals on a report page can interact with one another. For optimal performance, interactivity should be controlled and modified.
- Disabling unwanted interactivity reduces the number of queries fired at the backend and improves report performance.
Avoid using hierarchical filters to improve performance
- If you observe high page load times when using hierarchical filters, remove the hierarchical filters and instead use multiple filters for the hierarchy.
Limit complicated measures and aggregations in data models
- Push calculated columns and measures to the source where possible. The closer they are to the source, the higher the likelihood of improved performance.
- Create calculated measures instead of calculated columns.
- Use star schema for designing data models.
Import only necessary fields and tables instead of entire datasets
- Keep the model as narrow and lean as possible.
- Power BI works on columnar indexes; longer and leaner tables are preferred.
Creating falculated folumns, measures, and fields
- Use unique dataset field names for the dataset.
- Hide the fields which are not used directly but used only as a part of the calculation.
- Use sort order column, if you a need default sort on some specific columns.
- Whenever you need to perform any calculation based on already available fields, create calculated columns or measures as per the requirement.
MemSQL connector limitations with Zoomdata
The MemSQL connector supports all Zoomdata features, except for the following:
- Kerberos authentication
- Partitions
- User delegation
- Wild card filters, case-sensitive mode

