You are viewing an older version of this section. View current production version.
Columnstore
MemSQL supports storing and processing data using two types of stores, a completely in-memory rowstore and a disk-backed columnstore. The MemSQL rowstore and columnstores differ both in storage format (row, column) and in storage medium (RAM, disk - with flash or SSD recommended). MemSQL allows joining rowstore and columnstore data, thus allowing you to merge real-time and historical data together in a single query.
The rowstore is typically used for highly concurrent OLTP and mixed OLTP/analytical workloads. The columnstore is used primarily for applications where the data set does not fit in memory, the queries use mostly aggregates (in these cases the columnstore performs much better than the rowstore), or where cost-efficiency does not make using the in-memory rowstore possible.
The decision framework for choosing a rowstore or a columnstore is included later in this section. In general, since rowstores support a larger variety of workloads, they are a good starting point.
This section provides a conceptual overview of MemSQL’s columnstore and includes considerations for optimizing your database performance using the columnstore.
Creating a Columnstore Table
The columnstore is enabled by adding a CLUSTERED COLUMNSTORE index to a table. When defining a clustered columnstore index on a table, the table itself is physically stored using the columnstore. Currently, MemSQL supports one columnstore index per table. Combining columnstore indexes with other index types, except shard keys, is not currently supported.
Here’s an example of a query that creates a Columnstore table:
CREATE TABLE products (
ProductId INT,
Color VARCHAR(10),
Price INT,
dt DATETIME,
KEY (`Price`) USING CLUSTERED COLUMNSTORE ,
SHARD KEY (`dt`, `ProductId`)
);
As with any other MemSQL table, we define a SHARD KEY. We define it on user_id since it should allow for a more even distribution and preventing skew. It is also possible to randomly distribute data by having an empty shard key, with SHARD KEY().
To create a columnstore table, you must include CLUSTERED COLUMNSTORE key in the definition. Note that you can only have one CLUSTERED COLUMNSTORE key as well as the SHARD KEY. You cannot add any other key, including PRIMARY KEY, to the columnstore table.
If a CLUSTERED COLUMNSTORE is defined on a table, the rows of that table will be stored in a highly compressed columnar format on the disk. We describe the details of the format below. While MemSQL can execute any query on the Columnstore table that it can execute on Rowstore tables, some queries are more suitable for Columnstore tables than others. Some queries that can benefit
from using Columnstore include.
- Queries that need to scan several columns out of a table that contains many columns. Columnstore table will only materialize columns that it actually needs to perform the query.
- Queries that require to scan a lot of data in
CLUSTERED COLUMNSTOREkey order. Because the data is highly compressed, and is stored in order, such a scan can very efficiently utilize the processor cache. - Joins between two Columnstore tables on the
CLUSTERED COLUMNSTOREkey. Such a join will be executed as a Merge Join, resulting in a very good performance and very low memory overhead. - Queries with high selectivity filters on the
CLUSTERED COLUMNSTOREkey. By leveraging a technique calledsegment eliminationMemSQL can open only those Row Segments that actually contain relevant rows, significantly improving the performance of queries with high selectivity.
Columnstore tables are also not constrained by the amount of available memory, unlike Rowstore tables.
Conceptual Differences Between Row and Column Stores
Row-oriented stores, or “rowstores” are the most common type of data stores used by relational databases. As the name suggests, a rowstore treats each row as a unit and stores all fields for a given row together in the same physical location. This makes rowstores great for transactional workloads, where the database frequently selects, inserts, updates, and deletes individual rows, often referencing either most or all columns.
Column-oriented stores, or “columnstores” treat each column as a unit and stores segments of data for each column together in the same physical location. This enables two important capabilities, one is to scan each column individually, in essence being able to scan only the columns that are needed to execute a query with a high degree of locality. The other capability is that columnstores lend themselves well to compression, for example repeating and similar values can be easily compressed together. A simplified example is shown here:
Logical table and rowstore representation
| ProductId | Color | Price |
|---|---|---|
| 1 | Red | 10 |
| 2 | Red | 20 |
| 3 | Black | 20 |
| 4 | White | 20 |
Columnstore
| ProductId |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| Color |
|---|
| Red x 2 |
| Black |
| White |
“x 2” indicates that the value is repeated twice.
| Price |
|---|
| 10 |
| 20 x 3 |
“x 3” indicates that the value is repeated three times.
By physically organizing data by columns, the database is able to scan and aggregate data for individual columns very quickly, simply because less data needs to be scanned. This makes columnstores well suited to analytical workloads. The trade-off of using the columnstore is that it does not lend itself well to inserting or manipulating individual rows quickly. Columnstores are usually batch-loaded for optimal performance. The combination of efficient batch loading and processing of analytic queries contribute to columnstores’ frequently being used in data warehousing scenarios.
Choosing a Columnstore or Rowstore
The following table enumerates the strengths and intended uses of each storage engine.
| In-Memory Rowstore | Flash, SSD, or Disk-based Columnstore |
|---|---|
| Operational/transactional workloads | Analytical workloads |
| Fast inserts (appends) and updates over a small or large number of rows | Fast inserts (appends) over a small or large number of rows |
| Random seek performance | Fast aggregations and table scans |
| Updates are frequent | Updates are rare |
| Any types of deletes | Deletes that remove large numbers of rows |
| Compression |
How the MemSQL Columnstore Works
In MemSQL there are a few concepts that are important to understand in order to make the best possible use of the columnstore:
- Clustered columnstore index - A clustered columnstore index represents the full table structure and is its primary storage.
- Columnstore key column(s) - When creating a columnstore index one or more columns need to be defined as the key column(s) for the columnstore index. The data in the columnstore is stored in key column order and selecting a good columnstore key can significantly improve performance as covered later in this section.
- Row segment - A row segment represents a logical set of rows in the columnstore index. MemSQL stores metadata for each row segment in-memory which includes the total row count for the segment and a bitmask of which rows have been deleted.
- Column segment - Each row segment contains a column segment for every column in a table. The column segment is the unit of storage for a columnstore table and contains all values for a specific column with the row segment. Values in column segments are always stored in the same logical order across column segments within the same row segment. MemSQL stores metadata for each row segment in-memory which includes the minimum and maximum values contained within the segment. This metadata is used at query execution time determine whether a segment can possible match a filter, a process known as
segment elimination. - Sorted row segment group - A sorted row segment group represents a set of row segments that are sorted together on the columnstore key column(s). This means that within a sorted row segment group there will be no row segments with overlapping value ranges for the column(s) that make up the key for the columnstore index. Every time an
INSERT/UPDATE/LOADis run on the table, a new row segment group is created, information on how this affects query performance and how to minimize the number of sorted row segment groups is covered later in this section.
Below is an example of a MemSQL columnstore index on the Products table using the Price column as it’s key.
Column segments typically contain order of 10’s of thousands of rows, in this example the segment size is 5 rows for readability .
Logical table and rowstore representation
| ProductId | Color | Price | Qty |
|---|---|---|---|
| 1 | Red | 10 | 2 |
| 2 | Red | 20 | 2 |
| 3 | Black | 20 | 2 |
| 4 | White | 30 | 2 |
| 5 | Red | 20 | 2 |
| 6 | Black | 10 | 2 |
| 7 | White | 25 | 2 |
| 8 | Red | 30 | 2 |
| 9 | Black | 50 | 2 |
| 10 | White | 15 | 2 |
| 11 | Red | 5 | 2 |
| 12 | Red | 20 | 2 |
| 13 | Black | 35 | 2 |
| 14 | White | 30 | 2 |
| 15 | Red | 4 | 2 |
Columnstore - Each row segment contains one column segment per column in the table. For simplicity this example contains the initial load of the table and has a single sorted row segment group.
Sorted row segment group #1 of 1
Row segment #1 of 3
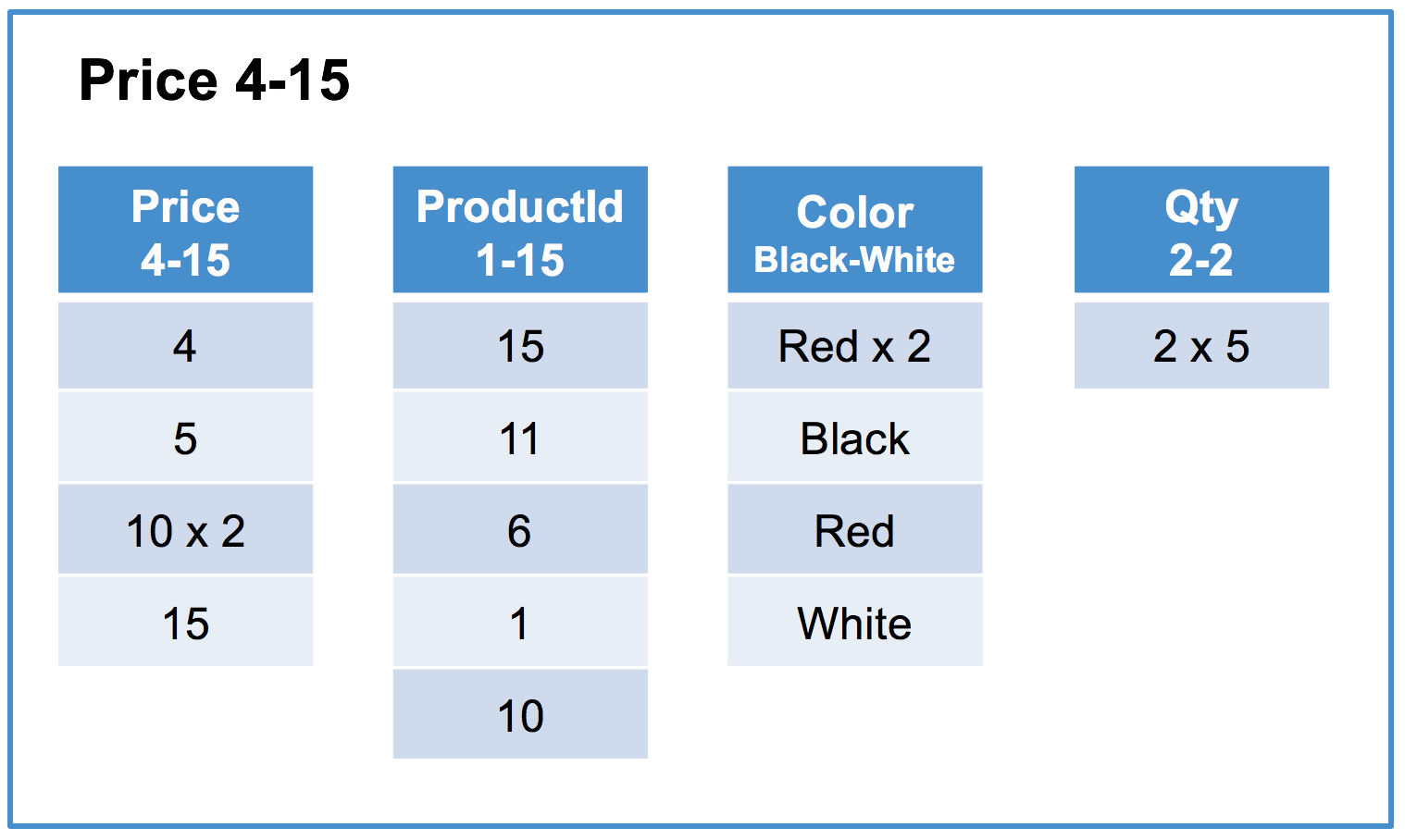
Row segment #2 of 3
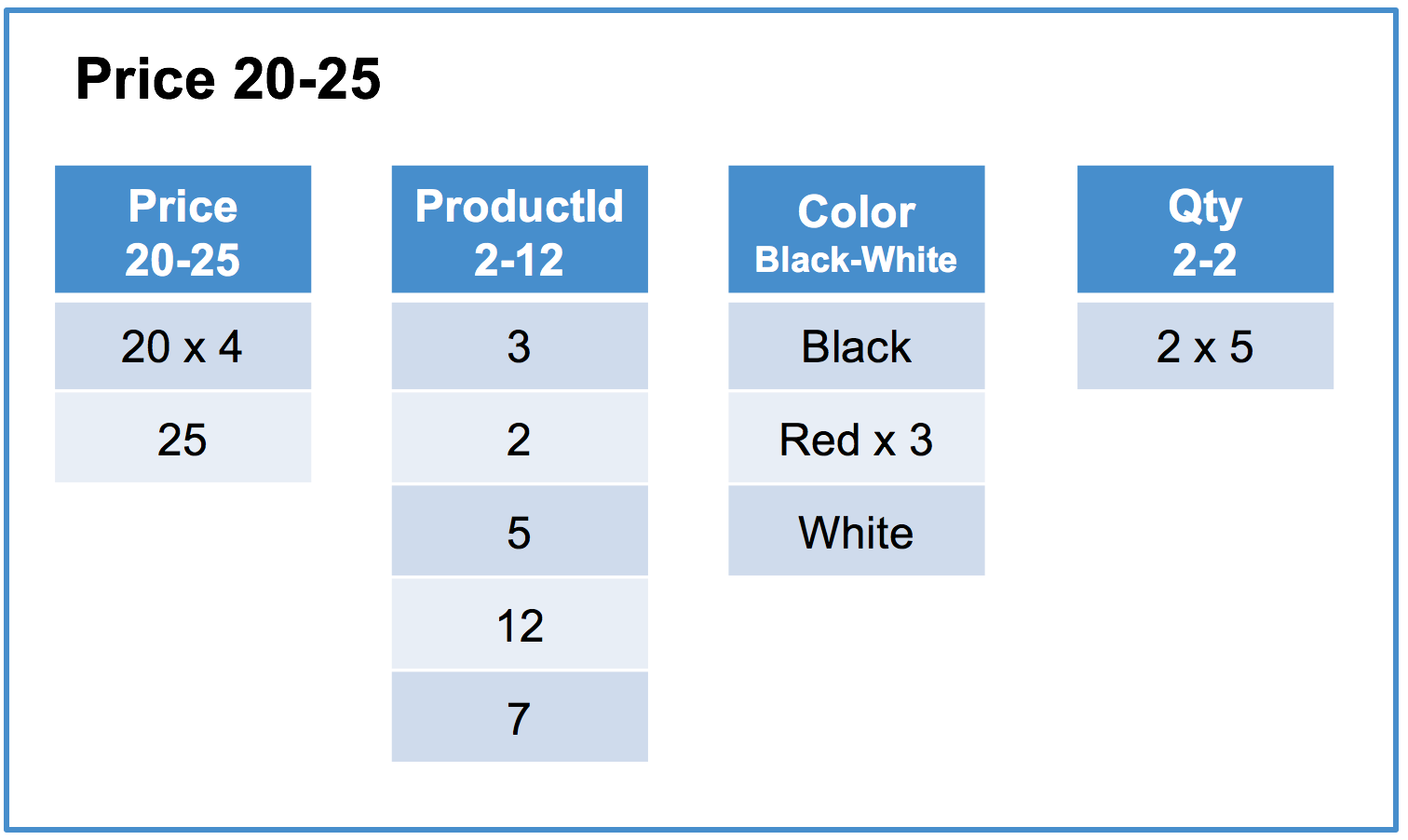
Row segment #3 of 3
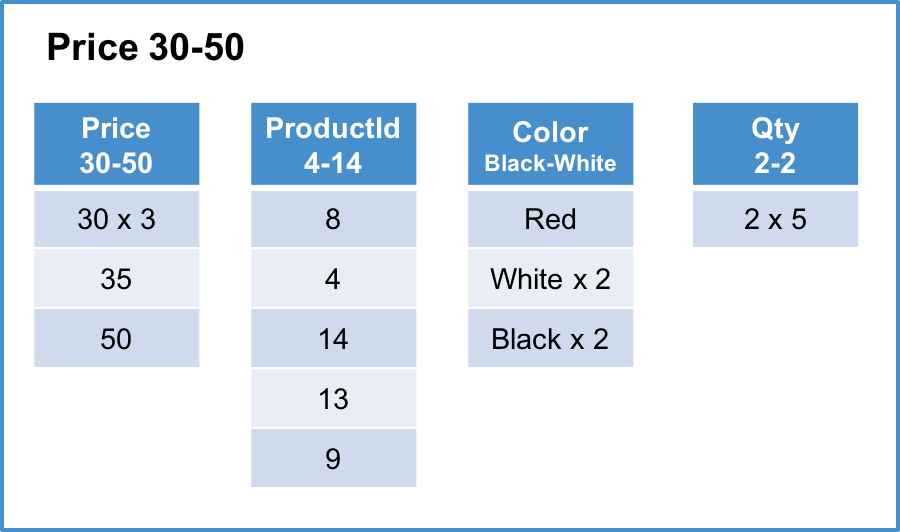
“x N” indicates that the value is repeated N times.
Creating Efficient Columnstore Queries
Queries against tables with a columnstore index in MemSQL can take advantage of five characteristics of a columnstore index:
- All queries will be able to take advantage of the fact that only the column segments containing columns referenced in the query will need to be scanned as well as the fact that the columnstore’s compression causes less data to need to be scanned. Taking the above table as an example the query
SELECT SUM(Qty) FROM Products;will only need to scan the threeQtycolumn segments each of which only contain a single value due to the compression. - Some queries can be satisfied simply by reading the in-memory meta data for column segments referenced in the query. As an example, the query
SELECT COUNT(*) FROM Products;will only need to read the row count and delete bitmask for all column segments of any column in meta data to produce its result, completely eliminating the need to read column segments from disk. Queries that use theMINorMAXaggregates can eliminate the need to read column segments from disk if no deletes have been performed against the column segment. - Some queries can reduce the number of segments that need to be read from disk by eliminating these segments based on the segment metadata (min and max values for the segment). The efficiency of this method depends on what percentage of segments that can actually be eliminated.
- For queries that filter on the key column of the columnstore index, segment elimination is typically very efficient as row segments within each row segment group will not have overlapping segments. For example, in the above table the query
SELECT AVG(Price), AVG(Qty) FROM Products WHERE Price BETWEEN 1 AND 10;will eliminate all segments exceptrow segment: #1 Column segment: Price 4-15androw segment: #1 Column segment: Qty 2-2which will be scanned. - For queries that filter on the non-key columns of the columnstore index, segment elimination can be much less valuable as row segments within each row segment group can have overlapping segments. For example, in the above table the query
SELECT AVG(Price) FROM Products WHERE Color = 'Red';will be forced to scan all segments for thePriceandColorcolumns as no segments can be eliminated (basically because the valueRedis contained in all segments of theColorcolumn)
- For queries that filter on the key column of the columnstore index, segment elimination is typically very efficient as row segments within each row segment group will not have overlapping segments. For example, in the above table the query
- Queries that join tables on columns that are the index columns of a columnstore index can be performed very efficiently through the use of a merge join algorithm allowing the join to be performed by simply scanning two segments that need to be joined in lock-step.
- For queries that have filters on data, such as strings, execution is performed without decompressing data from its serialized-for-disk format. This is only done in cases when run-time execution would be improved. Operations on compressed data currently work for string column filters with
=, != and INoperators.
Writing Columnstore Data
Unlike other columnstore implementations, MemSQL supports very fast, small-batch writes (such as single row inserts) directly into columnstore tables. This is implemented under the hood by storing hotly updated rows in a row-oriented skiplist before they flush to the columnstore. This is all handled automatically and behind the scenes, and rows are visible to reads as soon as they are saved to the rowstore.
When using MemSQL columnstore indexes the following are changes that can occur against the store.
- Insert - Inserts into a columnstore index will either go into the rowstore-backed row segment group or create a new columnstore-backed row segment group. This is automatically determined by the engine based on heuristics involving the size of the insert and the current state of the columnstore index. If an insert is large enough that it would write directly to the columnstore, it is an optimized insert. An optimized insert will load a set of data and pre-sort it in the order of the columnstore key column(s), this will cause the load to always create a single new row segment group.
LOAD DATAof more than 50,000 rows will produce an optimized insert. - Delete - Deleting a row in a columnstore index causes the row to be marked as deleted in the segment meta data leaving the data in place within the row segment. Segments which only contain deleted rows are removed, and the optimization process covered below will compact segments that require optimization.
- Update - An update in a columnstore index is internally performed as a delete followed by an insert. As with inserts, small enough updates will write to the rowstore-backed row segment group.
- Optimization - MemSQL has optimization routines that run automatically as well as can be started manually. These routines attempt to automatically merge row segment groups together in order to improve query efficiency. DML statements can be performed while columnstore optimizations take place.
- Automatic background optimization - MemSQL has background threads that automatically optimize columnstore indexes as needed. These optimizations are run in a single thread to minimize impact to concurrent query workloads. The background optimization will attempt to keep the number of row segment groups low but will not attempt to create a single row segment group due to the cost of this operation.
- Manual optimization - Regular - This optimization is started using the
OPTIMIZE TABLE <table_name>;statement and will cause the same process as the background optimization to be started; however, the process will be run using multiple threads to finish the optimization as fast as possible which may impact the performance of the currently run workload. See :ref:columnstore_mergersfor details. - Manual optimization - Full - This optimization is started using the
OPTIMIZE TABLE <table_name> FULL;statement and will start the manual optimization with the change that it will cause a single row segment group to be generated. This will cause the whole table to be sorted and should be expected to take more time than the other optimizations to complete. See :ref:columnstore_mergersfor details. - Manual optimization - Flush - This optimization is started using the
OPTIMIZE TABLE <table_name> FLUSH;statement and will flush any rows in the rowstore-backed row segment group into one or more columnstore-backed row segment groups.
Managing Columnstore Segments
Columnstore table will have the best performance if the rows in the table are in global sorted order across all the row segments. In reality, maintaining such an order is not feasible in a presence of continuous writes.
MemSQL uses an advanced algorithm that allows it to maintain the order as close to sorted as possible, while data is being ingested or updated. Such a process is called background merging and is constantly running in the background if the order of the row segments can be improved.
Background merger is optimistic, in a sense that if at any point it tries to move data around, which is also being changed by a concurrent UPDATE or DELETE query, it will discard all the work it has done so far and start over. It works on a small chunk of data at a time, so
it is always a relatively small amount of work that is being discarded. However, in a presence of a very heavy workload it can be a significant slow down compared to a pessimistic merger, which locks the row segments it is currently processing. A user can manually trigger a pessimistic merger by running an OPTIMIZE TABLE command. We will explain how to decide whether
such a command is necessary, and how to run it, below.
MemSQL uses a concept of a Sorted Row Segment Group to describe a set of Row Segments, that are sorted together. Row Segments form a Sorted Row Segment Group if and only if there’s an order on the Row Segments such that for each Row Segment the smallest row in it is no smaller than the largest row in any Row Segment before it. Here and below when we say that one row is smaller than another row, we mean that the values of columns of the CLUSTERED COLUMNAR key of that row are smaller than those of the other row.
If the data had a perfect global order, it would consist of a single Row Segment Group. If the data is in a completely random order, it is likely to comprise as many Row Segment Groups as there are Row Segments. The goal of the background merger is to move data around the Row Segments in such a way that the number of Segment Row Groups is as small as possible.
To inspect the current state of the Row Segment Groups of a particular table, run SHOW COLUMNAR MERGE STATUS FOR <table_name> query:
memsql> SHOW COLUMNAR MERGE STATUS FOR groups;
+- -----------------+- ------+- ------------------------+- ---------+- ----------+
| Merger | State | Plan | Progress | Partition |
+- -----------------+- ------+- ------------------------+- ---------+- ----------+
| (Current groups) | NULL | 741,16,1 | NULL | 0 |
| (Current groups) | NULL | 782,20 | NULL | 1 |
| (Current groups) | NULL | 701,40,5 | NULL | 2 |
| (Current groups) | NULL | 326,207,123,37,21,19,17 | NULL | 3 |
+- -----------------+- ------+- ------------------------+- ---------+- ----------+
4 rows in set (0.00 sec)
Let’s look closely at the first row of the result. According to it, the slice of the table that is stored on the partition 0 has three Sorted Row Segment Groups, one consisting of 741 Row Segments, one consisting of 16 Row Segments, and one consisting of a single Row Segment - a total of 758 Row Segments. Consider the impact of such a split into Sorted Row Segment Groups on a very simple query like
SELECT * FROM groups WHERE user_group = 15;
By the definition of the Sorted Row Segment Group, the very first row segment group will have at most one Row Segment that contains rows with user_group equal to 15, unless user_group = 15 is on the boundary of two Row Segments, or if there’s a large data skew and several Row Segments consist only of rows with user_group = 15. Similarly, at most one Row Segment in the second Sorted Row Segment Group contains relevant rows, and the only segment of the third Sorted Row Segment Group might also contain relevant groups. This way, only three Row Segments out of the total of 758 will in fact be opened and materialized. While the query in this example is very simple, similar reasoning works for significantly more complex queries.
Now take a look at the Row Segment Groups on partition 3. Clearly, it is significantly less optimized that the remaining three, and a select query like the one shown above will result in materializing 8 Row Segments. If the background merger is enabled, and no workload is running concurrently, within several seconds this partition would get optimized. However, in a presence of a heavy workload the optimistic background merger might fall behind. In this case it might be reasonable to manually trigger a pessimistic merger by calling:
memsql> OPTIMIZE TABLE groups
Empty set (32.36 sec)
If we run SHOW COLUMNAR MERGE STATUS as the OPTIMIZE TABLE is being executed, we might see the manual merger in action:
memsql> SHOW COLUMNAR MERGE STATUS FOR groups;
+- -----------------+- ---------+- ------------------------+- ---------+- ----------+
| Merger | State | Plan | Progress | Partition |
+- -----------------+- ---------+- ------------------------+- ---------+- ----------+
| (Current groups) | NULL | 741,16,1 | NULL | 0 |
| (Current groups) | NULL | 782,20 | NULL | 1 |
| (Current groups) | NULL | 701,40,5 | NULL | 2 |
| (Current groups) | NULL | 326,207,123,37,21,19,17 | NULL | 3 |
| Manual Merger | Working | 326+207+123+37+21+19+17 | 53.12% | 3 |
+- -----------------+- ------+- ---------------------------+- ---------+- ----------+
5 rows in set (0.00 sec)
What this new row indicates is that there’s a manual merger running on the partition 3, and that at this time it has done 53.12% of the work.
When the merger is done, the table now is in a better shape:
memsql> SHOW COLUMNAR MERGE STATUS FOR groups;
+- -----------------+- ------+- ---------+- ---------+- ----------+
| Merger | State | Plan | Progress | Partition |
+- -----------------+- ------+- ---------+- ---------+- ----------+
| (Current groups) | NULL | 741,16,1 | NULL | 0 |
| (Current groups) | NULL | 782,20 | NULL | 1 |
| (Current groups) | NULL | 701,40,5 | NULL | 2 |
| (Current groups) | NULL | 730,20 | NULL | 3 |
+- -----------------+- ------+- ---------+- ---------+- ----------+
4 rows in set (0.00 sec)
Note, that at no point any of the partitions was merged into a single Row Segment Group. The reason for that is that both optimistic and pessimistic merger use an advanced algorithm that is optimized to do small amortized chunks of work in a presence of concurrent writes and maintain data in a few Row Segment Groups, rather than to attempt to merge all the data into a single Row Segment Group. In cases when it is acceptable to sacrifice some time on data ingestion to achieve even higher SELECT performance, it is possible to run a manual command that merges data on each partition into a single Row Segment Group:
memsql> OPTIMIZE TABLE groups FULL
Empty set (57.36 sec)
memsql> SHOW COLUMNAR MERGE STATUS FOR groups;
+- -----------------+- ------+- -----+- ---------+- ----------+
| Merger | State | Plan | Progress | Partition |
+- -----------------+- ------+- -----+- ---------+- ----------+
| (Current groups) | NULL | 758 | NULL | 0 |
| (Current groups) | NULL | 802 | NULL | 1 |
| (Current groups) | NULL | 746 | NULL | 2 |
| (Current groups) | NULL | 750 | NULL | 3 |
+- -----------------+- ------+- -----+- ---------+- ----------+
4 rows in set (0.00 sec)
At this time any highly selective select will materialize only one Row Segment per partition.
Unlike OPTIMIZE TABLE <name>, which takes amortized time proportional to the size of recently loaded data, OPTIMIZE TABLE <name> FULL always takes time in the order of magnitude of the size of the entire table, unless data in that table is already sorted.
When inserting a small amount of rows into the columnstore table, an in-memory rowstore-backed segment is used to store the rows. As this rowstore-back segment fills, the background flusher periodically will flush these rows to disk. A rowstore-backed segment can be flushed to disk manually by running OPTIMIZE TABLE <table_name> FLUSH.
memsql> optimize table t flush;
Empty set (0.00 sec)
The maximum row count for a columnstore segment is controlled by the columnar_segment_rows variable. By default, columnar_segment_rows has a value of 102400. The size of the rowstore-back segment is controlled by the columnstore_disk_insert_threshold. This value is expressed as a fraction of columnar_segment_rows, which is the smallest disk-based row segment the background flusher will automatically create. This value defaults to .5. As a result, the minimum disk-backed row segment size will be columnar_segment_rows * columnstore_disk_insert_threshold or 51200 by default. Of course, if optimize table flush is manually run, the minimum size can be much smaller.
Prefetching
When a query matches multiple segments which are not currently cached in memory, it can benefit from prefetching. Prefetching improves performance on these types of queries by requesting the file from disk for the next segment while processing the rows of the current segment.
System Recommendations for Optimal Columnstore Performance
See the Columnstore Recommendations section of Installation Best Practices.

