You are viewing an older version of this section. View current production version.
How MemSQL Works
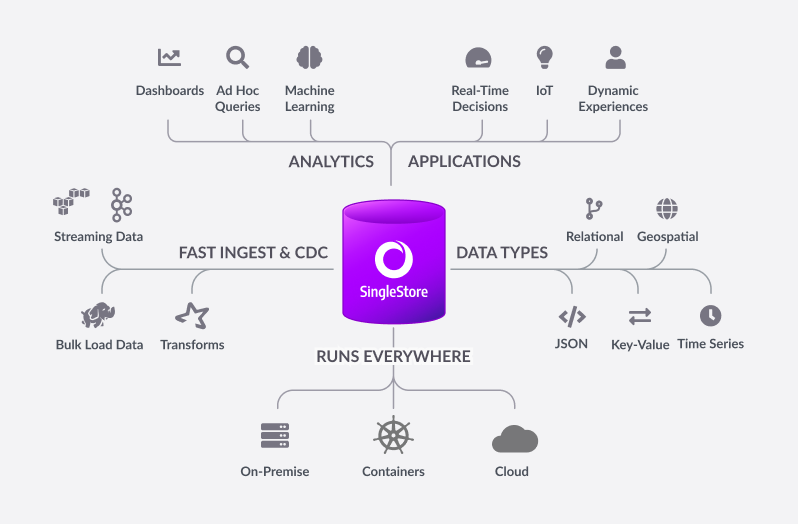
MemSQL is a distributed, relational database that handles both transactions and real-time analytics at scale. It is accessible through standard SQL drivers and supports ANSI SQL syntax including joins, filters, and analytical capabilities (e.g. aggregates, group by, and windowing functions).
MemSQL scales horizontally on cloud instances or industry-standard hardware, providing high throughput across a wide range of platforms. The MemSQL database maintains broad compatibility with common technologies in the modern data processing ecosystem (e.g. orchestration platforms, developer IDEs, and BI tools), so you can easily integrate it in your existing environment. It features an in-memory rowstore and an on-disk columnstore to handle both highly concurrent operational and analytical workloads. MemSQL also features a data ingestion technology called MemSQL Pipelines that streams large amounts of data at high throughput into the database with exactly-once semantics.
Try MemSQL using our Quick Start guides.
More detail about MemSQL is described in the sections below.
Data Ingestion
MemSQL can load data continuously or in bulk from a variety of sources. Popular loading sources includes files, a Kafka cluster, cloud repositories like Amazon S3, HDFS, or from other databases. As a distributed system, MemSQL ingests data streams using parallel loading to maximize throughput.
MemSQL Pipelines is an easy-to-use built-in capability that extracts, transforms, and loads external data using sources such as Kafka, S3, Azure Blob, and filesystems. It is ideal for scenarios where data from a supported source must be ingested and processed in real-time. This makes MemSQL Pipelines a good alternative to third-party middleware for basic ETL operations that must be executed as fast as possible, thus eliminating traditional long-running processes such as overnight batch jobs.
For bulk data load operations, MemSQL offers a LOAD DATA function that imports files in parallel to maximize performance.
For more information, see:
High-Performance for OLTP and OLAP Workloads
MemSQL is a highly-scalable distributed system. Data is sharded automatically amongst nodes in a cluster. Sharding optimizes query performance for both distributed aggregate queries and filtered queries with equality predicates. You can add nodes and redistribute shards (also known as partitions) as needed to scale your workload.
MemSQL also supports storing and processing data using an in-memory rowstore or a disk-based columnstore. The in-memory rowstore provides optimum real-time performance for transactional workloads. The disk-based columnstore is best for analytical workloads across large historical datasets. Rowstores are the default table type, but columnstores can be created by specifying a columnstore index type. A combination of the MemSQL rowstore and columnstore engines simplify your technology stack by allowing you to merge real-time and historical data in a single query.
In addition to handling mixed workloads, MemSQL supports high concurrency for simultaneous users. A distributed query optimizer evenly divides the processing workload to maximize the efficiency of CPU usage. Query plans are compiled to machine code and cached to expedite subsequent executions. A key feature of these compiled query plans is they do not pre-specify values for the parameters. This allows MemSQL to substitute the values upon request, which enables subsequent queries of the same structure to run quickly. Moreover, with MemSQL using Multi-Version Concurrency Control (MVCC) and lock-free data structures, data remains highly accessible, even amidst a high volume of concurrent reads and writes.
For more information, see:
Analyzing Data
MemSQL queries data using scalable standard SQL. The JDBC/OBDC interface enables widely-available BI tools such as Looker, Tableau, and Microstrategy to query and interact with data. Users or applications can connect and write SQL queries for custom visualizations or embedded analytic requirements.
MemSQL delivers a number of query performance capabilities to accelerate response time. These include:
-
True shared-nothing horizontal scaling and distributed parallel query execution
-
Columnstore query processing for fast aggregations and optimized disk consumption
-
Query compilation for faster execution
-
Query vectorization for highly efficient processing by leveraging streamlined, array-oriented processing, and on-chip CPU instructions
Deploy anywhere
MemSQL can be deployed anywhere in the cloud or on-premises without requiring specialty hardware to perform effectively; however, it will take advantage of single-instruction/multiple-data (SIMD) CPU instructions, specifically AVX2, and it is NUMA-aware to increase performance on newer machines. It can be deployed on bare metal, in VMs, and in the cloud.
For more information, see:
Durable and Redundant
In addition to being fast, consistent, and scalable, MemSQL is also durable. Transactions are committed to disk as log records and periodically compressed as snapshots of the entire database. If any node goes down, it can restart and use its logs to recover committed transactions.
MemSQL also supports high availability through the use of availability groups where nodes in the cluster share copies of data amongst each other in paired configurations. Nodes can failover as needed without the cluster going offline.
For more information, see:
Highly Compatible
MemSQL is an ODBC-compatible database. It is wire protocol compatible with MySQL so that applications that use a MySQL driver can connect to and use MemSQL transparently. MemSQL supports a subset of the MySQL syntax, plus extensions to support advanced features not in MySQL such as Distributed SQL, Geospatial, JSON, and Window Functions.
In addition to MySQL wire compatibility, MemSQL also integrates well with the stream processing framework Apache Spark to provide a simple way to create and manage real-time data pipelines.
For more client compatibility and integration information, see:

