Streamliner allows users to write and deploy custom extractors and transformers. It is recommended that users download the streamliner-starter and/or streamliner-examples repositories from GitHub. These repositories contain working examples of extractors and transforms and configured properly to compile out of the box.
The remainder of this document assumes the user has installed recent versions of Scala and SBT (Scala Build Tool).
MemSQL Streamliner Starter
The streamliner-starter repository contains “hello world” examples of extractors and transformers. To build the project, go to the top level of the streamliner-starter repository and run:
make build
This command will build a JAR and place it in streamliner-starter/target/scala-[SCALA_VERSION]/.
You can upload this JAR either through the MemSQL Ops web interface by clicking the “Change JAR” button, or on the command line using the following command:
memsql-ops interface-set-jar [/path/to/jar]
Uploading a Custom Spark Interface JAR
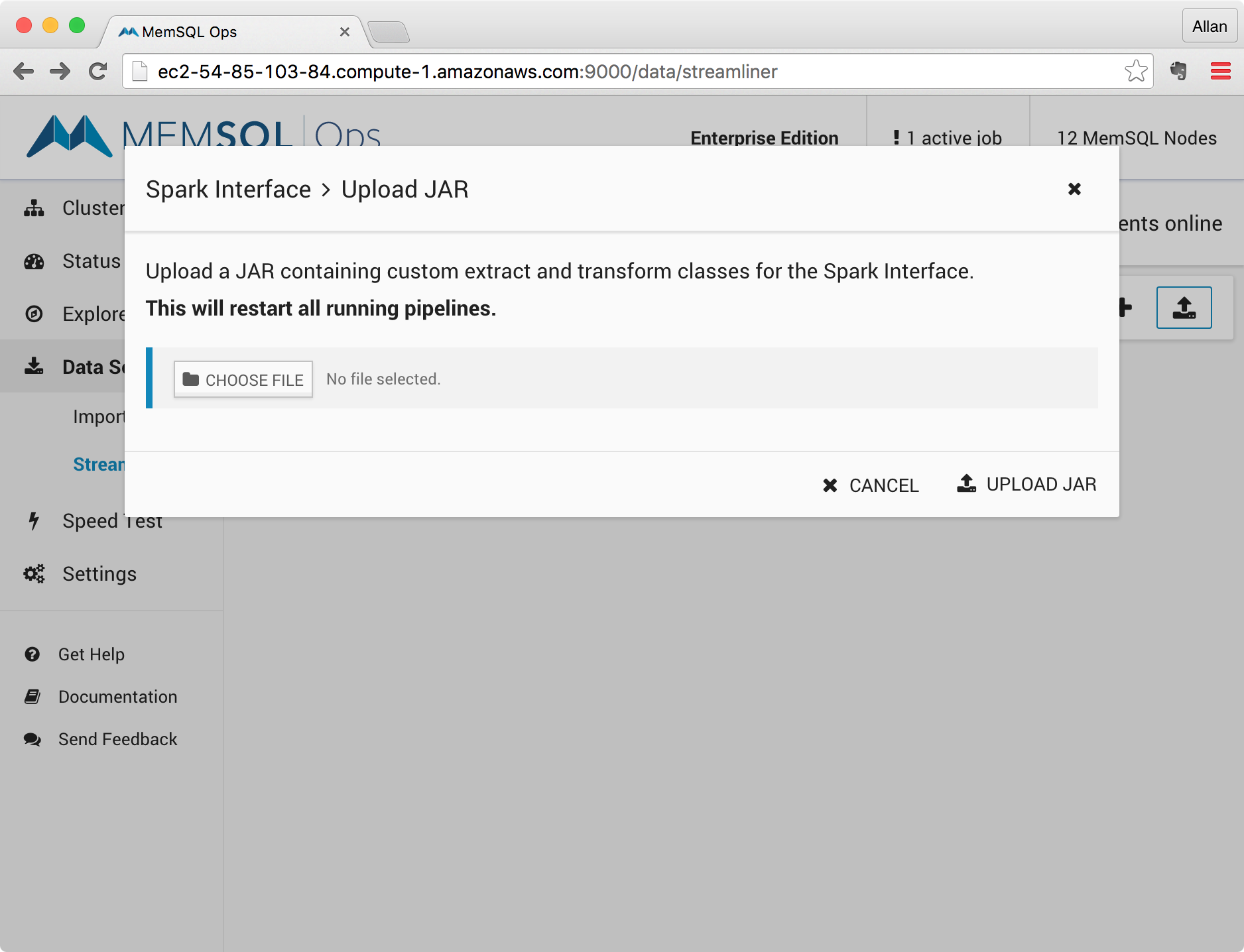
Via MemSQL Ops, you can upload a JAR containing custom extract and transform classes for the Spark Interface.
Uploading a new custom Spark Interface JAR will restart the Spark Interface, thus restarting all running pipelines.
On the Spark page in MemSQL Ops, click the Upload JAR button in the top-right corner. A popup window will open – choose your JAR file and confirm the upload.
Or via MemSQL Ops CLI:
$ memsql-ops interface-set-jar <path_to_jar>
Custom Extractor
To implement a custom extractor, extend the class SimpleByteArrayExtractor. This abstract class has three methods to override - two are optional, one must be implemented.
The nextRDD method must be implemented. nextRDD defines how Streamliner produces batches of records. The method returns Option[RDD[Array[Byte]]]. For more information, see the Scaladoc on Option <http://www.scala-lang.org/api/current/index.html#scala.Option>_. For more information on nextRDD, see our scaladoc.
The initialize and cleanup methods are both optional to implement. initialize is called when starting a pipeline and is meant for tasks like creating connections to external data sources. cleanup is called when stopping a pipeline and is meant for tasks like closing connections to external data sources.
For more detailed information on custom extractors and SimpleByteArrayExtractor, see our scaladoc.
Custom Transformer
To implement a custom transformer, extend the class SimpleByteArrayTransformer. This abstract class has one method, transform, which must be overridden.
The transform method takes an RDD of byte arrays (RDD[Array[Byte]]) output by an extractor and must return a DataFrame. There are several ways to create a DataFrame from an RDD. You can find some examples here <http://spark.apache.org/docs/latest/sql-programming-guide.html#interoperating-with-rdds>_. A simple way to do this is to explicitly define the schema of the DataFrame, as in the BasicTransformer example in streamliner-starter.
For more information on custom transformers and SimpleByteArrayTransformer, see our scaladoc.
Troubleshooting
Here are some of the common concerns from users compiling custom JARs:
Error found: JAR file does not include MemSQL etlLib.
Solution: Make sure that the build.sbt file does NOT set the com.memsql.memsqletl dependency as ‘provided’. This signals that the MemSQLETL library will be provided at a later time instead of packaged with the JAR.

