This topic describes MemSQL’s High Availability (HA) model and how to operate within it.
In MemSQL, the availability layer is responsible for mapping partitions to leaves (both masters and replicas) and is managed through a series of SQL commands that let you inspect and modify its state. You should familiarize yourself with MemSQL’s key concepts for an overview of leaf nodes and partitions before continuing.
High Availability Architecture
MemSQL exposes two modes of operation: redundancy-1 and redundancy-2 (see Administering a Cluster. In redundancy-1, there are no extra online copies of your data (all partitions are masters). In the event of a leaf node failure, your data is offline until you reintroduce the leaf back into the system. If your leaf node is irrecoverably lost, you can use the REBALANCE PARTITIONS … FORCE command to create empty replacement partitions instead of recovering your data. In redundancy-2, MemSQL handles node failures by promoting the appropriate replica partitions into masters so that your databases remain online. Of course, if all of your machines fail, then your data is unavailable until you recover enough machines or recreate the cluster from scratch. Each redundancy mode has an expected, balanced state.
When you recover a leaf in redundancy-1, by default it will be reintroduced to the cluster, with all the data that was on it restored.
Similarly, when you recover a leaf in redundancy-2, by default it will be reintroduced to the cluster. For each partition on that leaf one of the two things will happen:
- If that is the only instance of that partition (in other words, if the pair of this leaf is also down), the partition will be reintroduced to the cluster.
- If there’s another instance of that partition (usually on the pair of the leaf), then the partition on the newly recovered leaf will be discarded, and a new replica partition will be introduced, with data replicated from the existing copy.
You can disable master aggregator from automatically attaching leaves that become visible by setting a global variable auto_attach to Off. In this case you will need to manually run ATTACH LEAF to move that leaf into the online state once it is available. See Attaching - Examples below to see both automatic and manual approaches in action.
Every high availability command in MemSQL is online. As the command runs, you can continue to read and write to your data.
High availability commands can only be run on the master aggregator.
Enabling High Availability
Enabling High Availability via MemSQL Ops
As of version 4.0.31, MemSQL Ops supports enabling High Availability via Settings > Config.
During this process, Ops will move half of the leaves in the cluster from the availability group 1 into the availability group 2. This is considered an offline operation. As all partitions of all databases will be duplicated, each leaf node needs at least 50% free memory and disk space. In addition, the cluster must have an even number of leaves.
If you need to add more nodes to the cluster, we recommend doing it before enabling High Availability.
Note that currently MemSQL Ops does not support disabling High Availability.
Step 1. Install a new license (optional)
If you need to upgrade the license, for instance if your cluster is running MemSQL Community Edition and you are upgrading to MemSQL Enterprise Edition, you can do so from MemSQL Ops under Settings > Licenses.
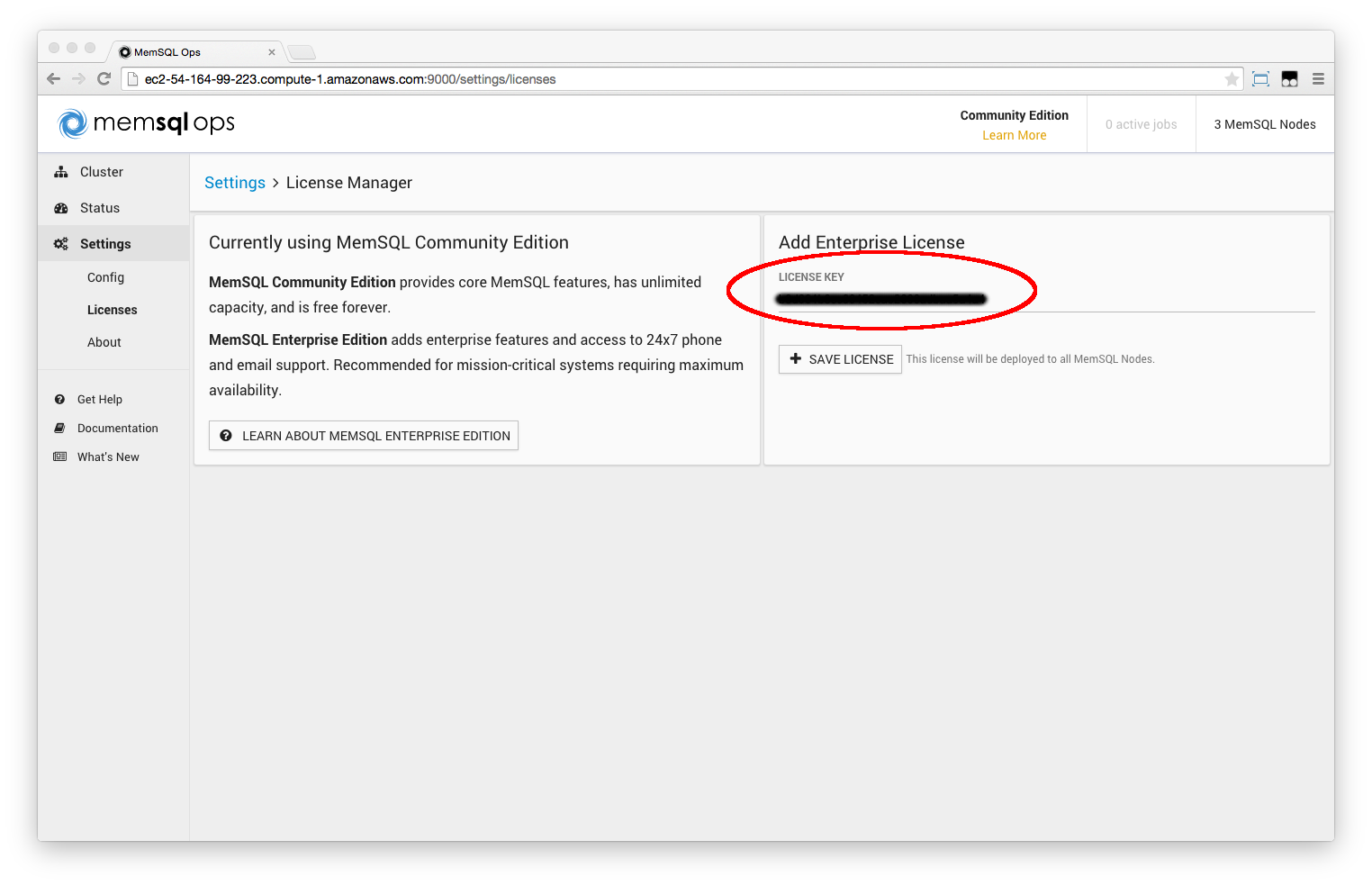
Or via MemSQL Ops CLI:
memsql-ops license-add --license-key <LICENSE>
Step 2. Enable High Availability
Under Settings > Config, select the checkbox High Availability within the same section, then confirm the operation.
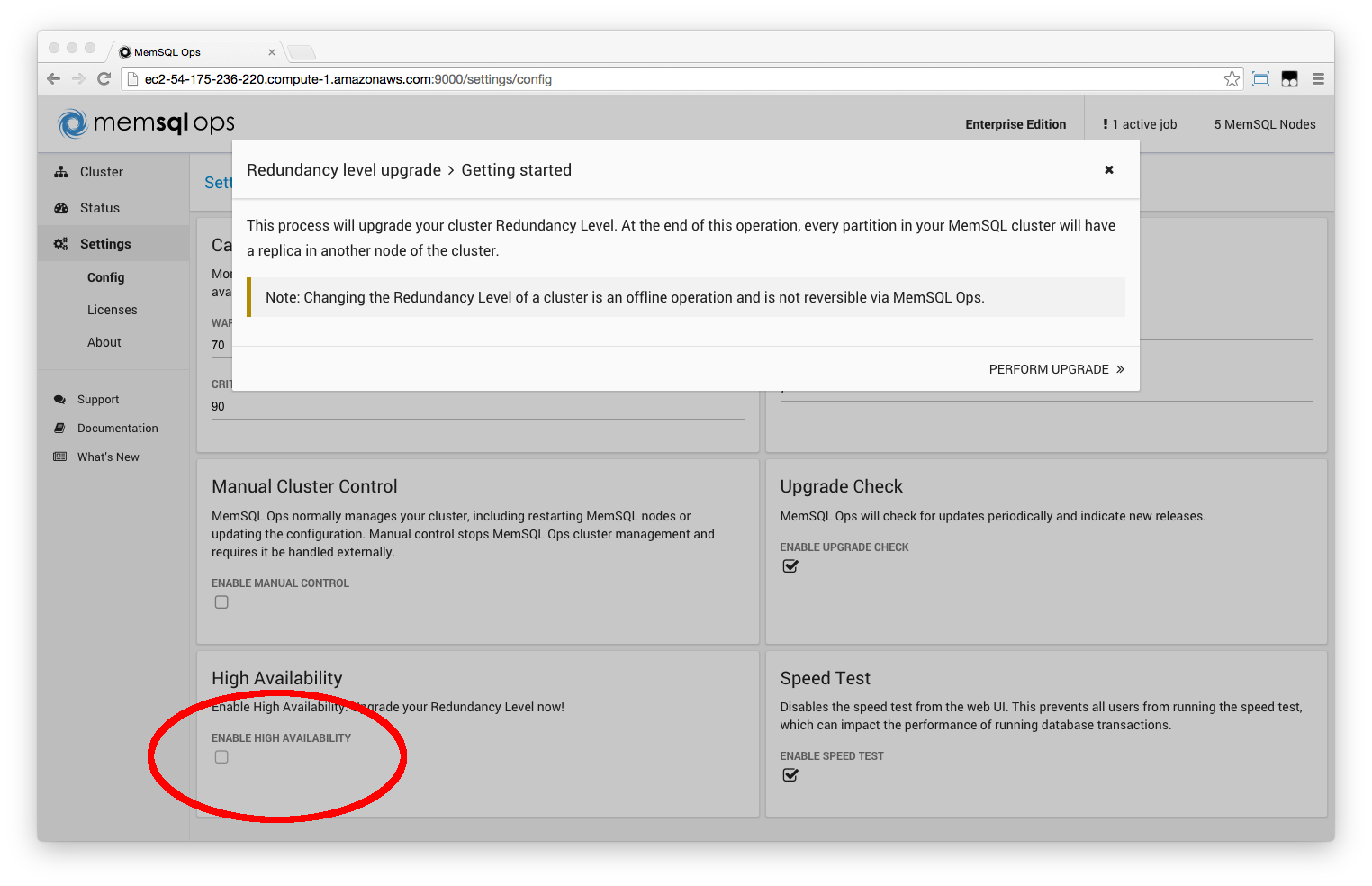
Or via MemSQL Ops CLI:
memsql-ops memsql-enable-high-availability
Manually Updating a Cluster from Redundancy-1 to Redundancy-2
Step 1. Update the redundancy_level value
On the Master Aggregator run:
memsql> SET @@GLOBAL.redundancy_level = 2;
This updates the current configuration and set the cluster to run in redundancy-2 operation mode.
In addition, update the MemSQL configuration file on the Master Aggregator to make sure the change is not lost whenever it will be restarted, and on all child aggregators to avoid inconsistencies in case a child is promoted to master.
memsql-ops memsql-list --memsql-role master aggregator -q | xargs -n 1 memsql-ops memsql-update-config --key redundancy_level --value 2 --no-prompt
You can safely ignore the message to restart MemSQL, as the configuration has already been updated via SET GLOBAL.
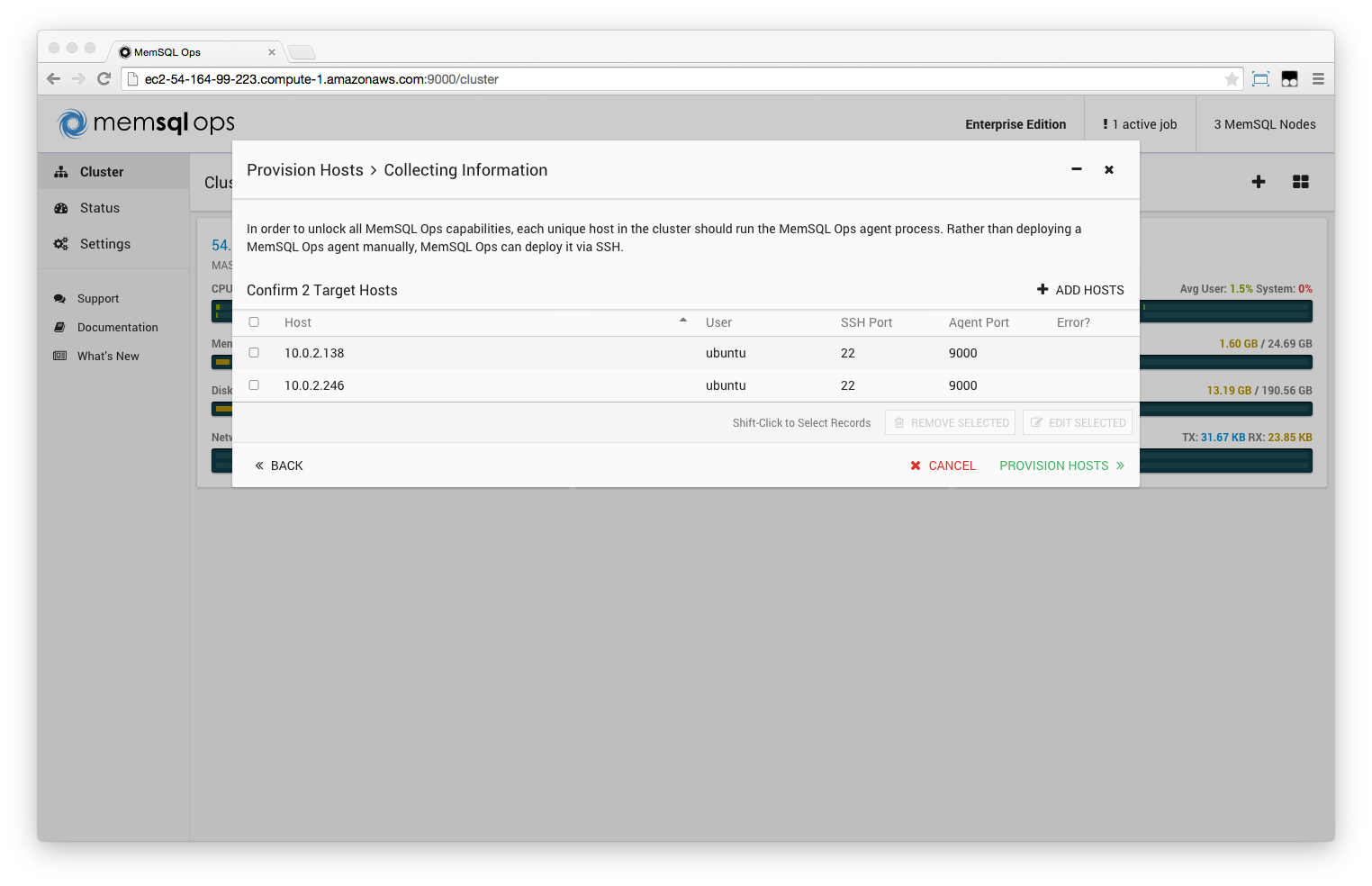
Step 2. Deploy MemSQL Ops on the new nodes
The cluster is now running in redundancy-2 operation mode, however all leaves belong to the availability group 1.
At this point, start an equal number of new nodes as the current number of leaf nodes, and deploy MemSQL Ops agents on all of them. In the example below, the cluster had 2 leaves, thus 2 new nodes are deployed.
memsql> SHOW LEAVES;
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency_ms |
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
| 10.0.3.7 | 3306 | 1 | NULL | NULL | online | 13 | 0.581 |
| 10.0.0.138 | 3306 | 1 | NULL | NULL | online | 13 | 0.408 |
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
2 rows in set (0.00 sec)
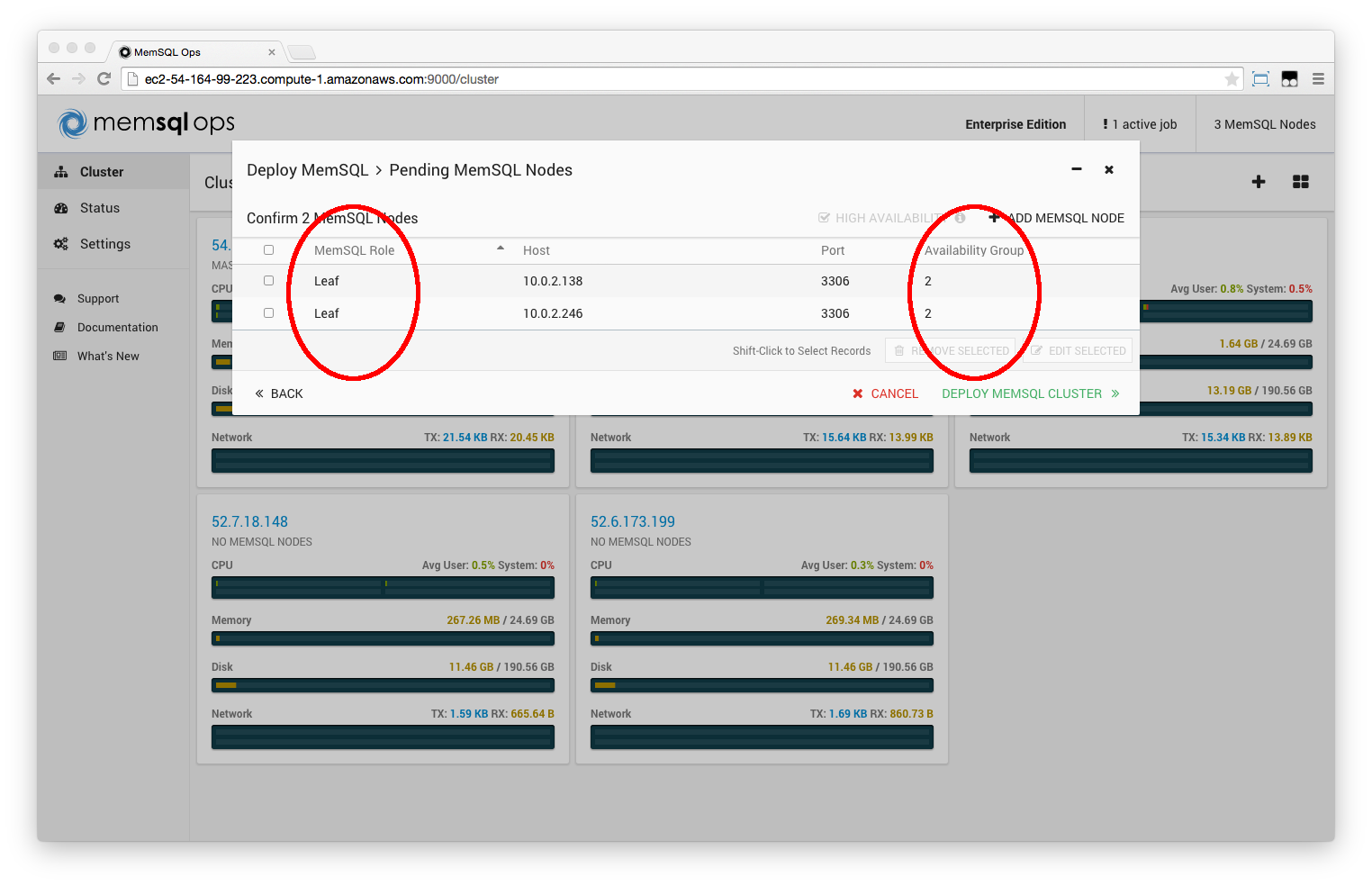
Step 3. Install MemSQL on the new nodes, setting availability group 2
Deploy MemSQL on the new nodes. Make sure to edit all nodes, and select MemSQL Role: Leaf and Availability Group: 2.
After deployment, you can verify that your leaves are up and running.
memsql> SHOW LEAVES;
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency_ms |
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
| 10.0.3.7 | 3306 | 1 | 10.0.2.123 | 3306 | online | 13 | 0.495 |
| 10.0.0.138 | 3306 | 1 | 10.0.2.246 | 3306 | online | 13 | 0.410 |
| 10.0.2.123 | 3306 | 2 | 10.0.3.7 | 3306 | online | 1 | 0.403 |
| 10.0.2.246 | 3306 | 2 | 10.0.0.138 | 3306 | online | 1 | 0.319 |
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
4 rows in set (0.00 sec)
Step 4. Rebalance the cluster
Finally, you need to rebalance the cluster, by running REBALANCE PARTITIONS for all your databases. On the Master Aggregator, you can run the following script:
for DB in `mysql -u root -h 127.0.0.1 --batch --skip-pager --skip-column-names --execute="SHOW DATABASES" | grep -vE "^(memsql|information_schema|sharding)$"`
do
echo "Rebalancing partitions on DB $DB"
mysql -u root -h 127.0.0.1 --batch --execute "REBALANCE PARTITIONS ON $DB"
done
Note that, before running REBALANCE PARTITIONS , only 1 master partition is still available for each database, which means high availability is not yet provided. For instance:
memsql> SHOW PARTITIONS ON memsql_demo;
+---------+------------+------+--------+--------+
| Ordinal | Host | Port | Role | Locked |
+---------+------------+------+--------+--------+
| 0 | 10.0.3.7 | 3306 | Master | 0 |
| 1 | 10.0.3.7 | 3306 | Master | 0 |
| 2 | 10.0.0.138 | 3306 | Master | 0 |
| 3 | 10.0.0.138 | 3306 | Master | 0 |
| 4 | 10.0.3.7 | 3306 | Master | 0 |
| 5 | 10.0.3.7 | 3306 | Master | 0 |
| 6 | 10.0.0.138 | 3306 | Master | 0 |
| 7 | 10.0.3.7 | 3306 | Master | 0 |
| 8 | 10.0.0.138 | 3306 | Master | 0 |
| 9 | 10.0.3.7 | 3306 | Master | 0 |
| 10 | 10.0.0.138 | 3306 | Master | 0 |
| 11 | 10.0.0.138 | 3306 | Master | 0 |
| 12 | 10.0.3.7 | 3306 | Master | 0 |
| 13 | 10.0.3.7 | 3306 | Master | 0 |
| 14 | 10.0.0.138 | 3306 | Master | 0 |
| 15 | 10.0.0.138 | 3306 | Master | 0 |
+---------+------------+------+--------+--------+
16 rows in set (0.00 sec)
memsql> REBALANCE partitions on memsql_demo;
Query OK, 1 row affected (1 min 10.19 sec)
After running REBALANCE PARTITIONS, notice that both Master and replica partitions exist within the database cluster.
memsql> SHOW PARTITIONS ON memsql_demo;
+---------+------------+------+--------+--------+
| Ordinal | Host | Port | Role | Locked |
+---------+------------+------+--------+--------+
| 0 | 10.0.2.123 | 3306 | Master | 0 |
| 0 | 10.0.3.7 | 3306 | Slave | 0 |
| 1 | 10.0.2.123 | 3306 | Master | 0 |
| 1 | 10.0.3.7 | 3306 | Slave | 0 |
| 2 | 10.0.2.246 | 3306 | Master | 0 |
| 2 | 10.0.0.138 | 3306 | Slave | 0 |
| 3 | 10.0.2.246 | 3306 | Master | 0 |
| 3 | 10.0.0.138 | 3306 | Slave | 0 |
| 4 | 10.0.2.123 | 3306 | Master | 0 |
| 4 | 10.0.3.7 | 3306 | Slave | 0 |
| 5 | 10.0.2.123 | 3306 | Master | 0 |
| 5 | 10.0.3.7 | 3306 | Slave | 0 |
| 6 | 10.0.2.246 | 3306 | Master | 0 |
| 6 | 10.0.0.138 | 3306 | Slave | 0 |
| 7 | 10.0.3.7 | 3306 | Master | 0 |
| 7 | 10.0.2.123 | 3306 | Slave | 0 |
| 8 | 10.0.2.246 | 3306 | Master | 0 |
| 8 | 10.0.0.138 | 3306 | Slave | 0 |
| 9 | 10.0.3.7 | 3306 | Master | 0 |
| 9 | 10.0.2.123 | 3306 | Slave | 0 |
| 10 | 10.0.0.138 | 3306 | Master | 0 |
| 10 | 10.0.2.246 | 3306 | Slave | 0 |
| 11 | 10.0.0.138 | 3306 | Master | 0 |
| 11 | 10.0.2.246 | 3306 | Slave | 0 |
| 12 | 10.0.3.7 | 3306 | Master | 0 |
| 12 | 10.0.2.123 | 3306 | Slave | 0 |
| 13 | 10.0.3.7 | 3306 | Master | 0 |
| 13 | 10.0.2.123 | 3306 | Slave | 0 |
| 14 | 10.0.0.138 | 3306 | Master | 0 |
| 14 | 10.0.2.246 | 3306 | Slave | 0 |
| 15 | 10.0.0.138 | 3306 | Master | 0 |
| 15 | 10.0.2.246 | 3306 | Slave | 0 |
+---------+------------+------+--------+--------+
32 rows in set (0.00 sec)
Disabling High Availability
To disable High Availability, all leaves in availability group 2 need to be deleted and either removed from the cluster or re-added into the availability group 1.
Note that the cluster should be in manual control mode of operation, or MemSQL Ops will automatically re-added the leaves.
Step 1. Enable manual cluster control
From MemSQL Ops under Settings > Config > Manual Cluster Control, check Enable Manual Control.
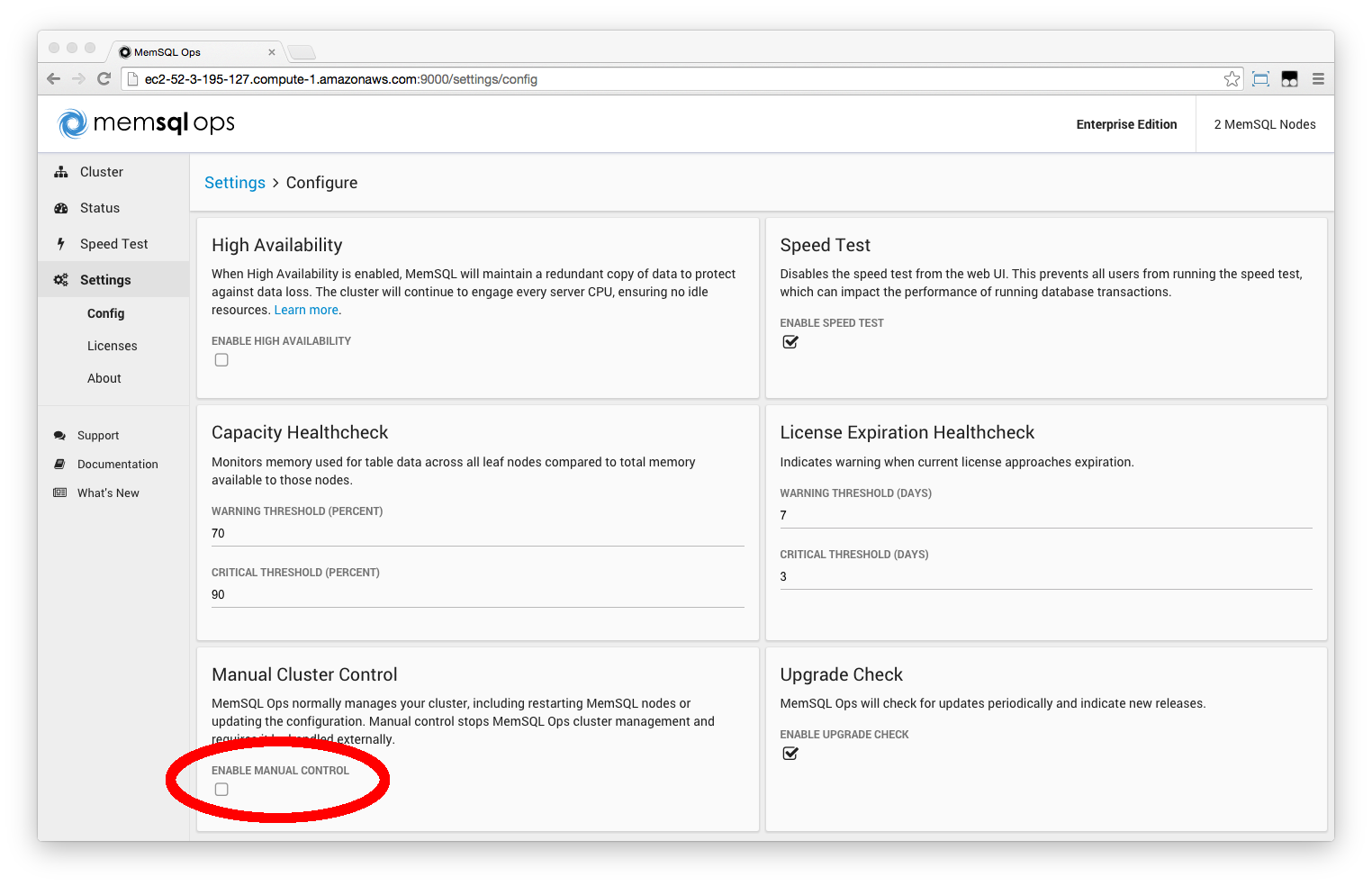
Or via MemSQL Ops CLI:
memsql-ops cluster-manual-control --enable
Step 2. Remove all leaves in availability group 2
Connect to MemSQL, e.g. on the Master Aggregator, and for each leaf in availability group 2 run:
memsql> REMOVE LEAF 'host';
memsql> SHOW LEAVES;
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency_ms |
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
| 10.0.3.7 | 3306 | 1 | 10.0.2.123 | 3306 | online | 13 | 0.495 |
| 10.0.0.138 | 3306 | 1 | 10.0.2.246 | 3306 | online | 13 | 0.410 |
| 10.0.2.123 | 3306 | 2 | 10.0.3.7 | 3306 | online | 1 | 0.403 |
| 10.0.2.246 | 3306 | 2 | 10.0.0.138 | 3306 | online | 1 | 0.319 |
+------------+------+--------------------+------------+-----------+--------+--------------------+------------------------------+
4 rows in set (0.00 sec)
You should run:
memsql> REMOVE LEAF '10.0.2.123';
Query OK, 1 row affected (0.31 sec)
memsql> REMOVE LEAF '10.0.2.246';
Query OK, 1 row affected (0.29 sec)
memsql> SHOW LEAVES;
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency_ms |
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
| 10.0.3.7 | 3306 | 1 | NULL | NULL | online | 13 | 0.581 |
| 10.0.0.138 | 3306 | 1 | NULL | NULL | online | 13 | 0.408 |
+------------+------+--------------------+-----------+-----------+--------+--------------------+------------------------------+
2 rows in set (0.00 sec)
Step 3. Update the redundancy_level value
On the Master Aggregator run:
memsql> SET @@GLOBAL.redundancy_level = 1;
This updates the current configuration and set the cluster to run in redundancy-1 operation mode.
In addition, update the MemSQL configuration file on the Master Aggregator to make sure the change is not lost whenever it will be restarted, and on all child aggregators to avoid inconsistencies in case a child is promoted to master.
memsql-ops memsql-list --memsql-role master aggregator -q | xargs -n 1 memsql-ops memsql-update-config --key redundancy_level --value 1 --no-prompt
You can safely ignore the message to restart MemSQL, as the configuration has already been updated via SET GLOBAL.
Step 4. Disable manual cluster control
Similarly as in Step 1, from MemSQL Ops under Settings > Config > Manual Cluster Control, uncheck Enable Manual Control.
Or via MemSQL Ops CLI:
memsql-ops cluster-manual-control --disable
Step 5. Re-add leaves into availability group 1 (optional)
Optionally, you can re-add the deleted leaves into the availability group 1. This also requires rebalancing partitions and clearing the orphan ones.
To re-add the leaves into the availability group 1, on the Master Aggregator run:
memsql> ADD LEAF user[:'password']@'host'[:port] INTO GROUP 1;
Next, rebalance the cluster by running REBALANCE PARTITIONS for all databases. On the Master Aggregator, you can run the following script:
for DB in `mysql -u root -h 127.0.0.1 --batch --skip-pager --skip-column-names --execute="SHOW DATABASES" | grep -vE "^(memsql|information_schema|sharding)$"`
do
echo "Rebalancing partitions on DB $DB"
mysql -u root -h 127.0.0.1 --batch --execute "REBALANCE PARTITIONS ON $DB"
done
The cluster will now contains orphan partitions, in fact the old replica partitions. Orphan partitions can be shown by running SHOW CLUSTER STATUS, and deleted by running on the Master Aggregator:
memsql> CLEAR ORPHAN DATABASES;
High Availability Commands
Summary of High Availability Commands
High-level Commands
Use the following commands to manage high availability in MemSQL.
ADD LEAF REMOVE LEAF ATTACH LEAF DETACH LEAF REBALANCE PARTITIONS EXPLAIN REBALANCE PARTITIONS SHOW REBALANCE STATUS For more information, see Administering a Cluster.
Working with Leaves
Leaf Nodes are responsible for storing slices of data in the distributed system. Each leaf is just a MemSQL single-box server consisting of several Partitions – each partition is just a database on that server. If you have a database named test and run SHOW DATABASES on a leaf, you will see names resembling test_5 (this would be partition 5 for database test).
Use the following commands to work with leaves:
- ADD LEAF adds previously unknown nodes into the cluster.
- REMOVE LEAF first rebalances away a leaf node’s partitions and then removes it from the list of - leaves in SHOW LEAVES.
- ATTACH LEAF transitions a detached node back into the online state (see Leaf States). It can also be used to introduce a new, previously unknown node, to the cluster. In that case, unlike ADD LEAF ,
- ATTACH LEAF will analyze the data present on the leaf node and try to reintroduce it back into the system if possible. In redundancy-2, ATTACH LEAF will automatically rebalance partitions between a node and its pair to equalize the number of master and replica partitions across the pair. This is an example of an HA command converging the state of the cluster towards balance.
- DETACH LEAF transitions the leaf to the detached state instead of removing it.
You should run REMOVE LEAF on leaves that you no longer wish to track as part of the distributed system. If you plan to run maintenance on a machine and want to temporarily relieve it from serving data, you should detach it first, perform the necessary maintenance, restart it, and then use ATTACH LEAF to reintroduce it. ATTACH LEAF will automatically recover what data it can from the machine and rebalance partitions with its pair to restore balance.
During or after running ATTACH LEAF , REMOVE LEAF , or DETACH LEAF , you can run SHOW REBALANCE STATUS STATUS ON db on any database to see what low-level partition operations the aggregator ran as part of the operation.
Rebalancing the Cluster
HA operations in MemSQL generate a rebalance plan: a series of low-level commands that converge the cluster towards a balanced state. A redundancy-1 cluster is balanced if every online leaf has an equal number of partitions. A redundancy-2 cluster is balanced if every pair of leaves has an equal number of partitions, and, within a pair, each leaf has an equal number of master and replica partitions.
Since partitions are per-database, each rebalance plan is also per-database. ATTACH LEAF , REMOVE LEAF , DETACH LEAF , and REBALANCE PARTITIONS all work this way.
MemSQL will never auto-rebalance your data in the background. In the event of a failure, MemSQL will promote the partitions that it needs to bring the database back online. Once you’ve recovered or recreated the failed leaf nodes, you can proceed by running the relevant HA commands to rebalance the cluster. This model enables you to trigger a complex rebalance operation with a simple SQL command, and it also prevents expensive background work from affecting the performance of your application without your explicit administrative consent.
The REBALANCE PARTITIONS command examines the state of partitions and leaves for a particular database, generates a plan to rebalance the partitions across the online leaves, and executes that plan. You can use the EXPLAIN REBALANCE PARTITIONS ON db to view the plan that REBALANCE PARTITIONS on db would execute. If this command returns an empty result, then the database is balanced. The following is an example output from EXPLAIN REBALANCE PARTITIONS run on a small sample cluster:
memsql> EXPLAIN REBALANCE PARTITIONS ON test;
+-------------------+---------+-------------+-------------+-------+
| Action | Ordinal | Target_Host | Target_Port | Phase |
+-------------------+---------+-------------+-------------+-------+
| COPY PARTITION | 1 | leaf-6 | 3306 | 2 |
| COPY PARTITION | 3 | leaf-8 | 3306 | 2 |
| COPY PARTITION | 5 | leaf-6 | 3306 | 2 |
| COPY PARTITION | 7 | leaf-8 | 3306 | 2 |
| PROMOTE PARTITION | 1 | leaf-6 | 3306 | 6 |
| PROMOTE PARTITION | 3 | leaf-8 | 3306 | 6 |
| COPY PARTITION | 1 | leaf-2 | 3306 | 7 |
| COPY PARTITION | 3 | leaf-4 | 3306 | 7 |
+-------------------+---------+-------------+-------------+-------+
8 rows in set (0.00 sec)
Each action corresponds to a low-level command described in Low Level Commands . The Ordinal is the target partition’s ordinal, and the Target_Host and Target_Port correspond to the destination leaf. Any two operations in the same Phase can be run in parallel and phases are run in order. For example, the aggregator can run COPY PARTITION on partitions test:1 and test:3 in parallel. The exact meaning of what each phase means is arbitrary and depends on the particular rebalance operation.
To execute this plan (assuming the state of the cluster does not change before you proceed), you can run the REBALANCE PARTITIONS command:
memsql> REBALANCE PARTITIONS ON test;
Query OK, 1 row affected (9.80 sec)
The main use-case for the REBALANCE PARTITIONS command is to rebalance data onto new leaf nodes in the cluster. This situation can arise from adding new leaf nodes to the cluster to expand capacity, or if leaf nodes terminate irrecoverably and you wish to replace them with new nodes. For common leaf-failure scenarios, ATTACH LEAF will automatically perform the necessary rebalance operations on the affected leaf nodes.
Although rebalance operations can take some time to complete, you can continue to read and write data to the database while it runs (the operation is online). While REBALANCE PARTITIONS runs, use the SHOW REBALANCE STATUS command to examine its running state:
memsql> SHOW REBALANCE STATUS ON test;
+-------------------+---------+-------------+-------------+-------+-----------+--------------+
| Action | Ordinal | Target_Host | Target_Port | Phase | Status | Running_Time |
+-------------------+---------+-------------+-------------+-------+-----------+--------------+
| COPY PARTITION | 1 | leaf-6 | 3306 | 2 | running | 1574 |
| COPY PARTITION | 3 | leaf-8 | 3306 | 2 | running | 1574 |
| COPY PARTITION | 5 | leaf-6 | 3306 | 2 | running | 1574 |
| COPY PARTITION | 7 | leaf-8 | 3306 | 2 | running | 1574 |
| PROMOTE PARTITION | 1 | leaf-6 | 3306 | 6 | scheduled | NULL |
| PROMOTE PARTITION | 3 | leaf-8 | 3306 | 6 | scheduled | NULL |
| COPY PARTITION | 1 | leaf-2 | 3306 | 7 | scheduled | NULL |
| COPY PARTITION | 3 | leaf-4 | 3306 | 7 | scheduled | NULL |
+-------------------+---------+-------------+-------------+-------+-----------+--------------+
8 rows in set (0.00 sec)
The output is the same as EXPLAIN REBALANCE PARTITIONS with the addition of two new columns. Status is one of scheduled, running, or completed. For running or completed commands, Running_Time indicates the time in milliseconds that has been spent running the particular low-level command.
After REBALANCE PARTITIONS completes, SHOW REBALANCE STATUS displays a summary of the last rebalance operation until the next one is run.
memsql> SHOW REBALANCE STATUS ON test;
+-------------------+---------+-------------+-------------+-------+---------+--------------+
| Action | Ordinal | Target_Host | Target_Port | Phase | Status | Running_Time |
+-------------------+---------+-------------+-------------+-------+---------+--------------+
| COPY PARTITION | 1 | leaf-6 | 3306 | 2 | success | 2870 |
| COPY PARTITION | 3 | leaf-8 | 3306 | 2 | success | 2903 |
| COPY PARTITION | 5 | leaf-6 | 3306 | 2 | success | 2903 |
| COPY PARTITION | 7 | leaf-8 | 3306 | 2 | success | 2903 |
| PROMOTE PARTITION | 1 | leaf-6 | 3306 | 6 | success | 4131 |
| PROMOTE PARTITION | 3 | leaf-8 | 3306 | 6 | success | 4165 |
| COPY PARTITION | 1 | leaf-2 | 3306 | 7 | success | 2606 |
| COPY PARTITION | 3 | leaf-4 | 3306 | 7 | success | 2627 |
+-------------------+---------+-------------+-------------+-------+---------+--------------+
8 rows in set (0.00 sec)
ATTACH LEAF, REMOVE LEAF , and DETACH LEAF also generate and execute plans for every database relevant to the target leaf node.
Attaching Leaves - Examples
In this section, we will walk through a full example of running ATTACH LEAF on redundancy-1 and ``redundancy-2` clusters. Redundancy-1 vs. redundancy-2 clusters are explained earlier in Managing High Availability.
ATTACH LEAF In Redundancy-1
Let’s walk through a full example in a redundancy-1 cluster. This cluster has four leaves leaf-1 through leaf-4 and a database named test. In this example, leaf-4 will fail, and we will recover and reintroduce it into the system with ATTACH LEAF.
Here is the initial state of the cluster:
-- SHOW LEAVES returns all the leaves in the cluster and their current states
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | NULL | NULL | online | 2 | 0.397 |
| leaf-2 | 3306 | 1 | NULL | NULL | online | 2 | 0.397 |
| leaf-3 | 3306 | 1 | NULL | NULL | online | 2 | 0.349 |
| leaf-4 | 3306 | 1 | NULL | NULL | online | 2 | 0.363 |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
4 rows in set (0.00 sec)
-- SHOW PARTITIONS returns all the partitions on a given database.
memsql> SHOW PARTITIONS ON test;
+---------+--------+-------+--------+
| Ordinal | Host | Port | Role |
+---------+--------+-------+--------+
| 0 | leaf-1 | 3306 | Master |
| 1 | leaf-2 | 3306 | Master |
| 2 | leaf-3 | 3306 | Master |
| 3 | leaf-4 | 3306 | Master |
| 4 | leaf-1 | 3306 | Master |
| 5 | leaf-2 | 3306 | Master |
| 6 | leaf-3 | 3306 | Master |
| 7 | leaf-4 | 3306 | Master |
+---------+--------+-------+--------+
8 rows in set (0.00 sec)
-- You can query in INFORMATION_SCHEMA.DISTRIBUTED_PARTITIONS to slice
-- and dice the partitions map
memsql> SELECT * FROM INFORMATION_SCHEMA.DISTRIBUTED_PARTITIONS
-> WHERE DATABASE_NAME='test' AND Host='leaf-4';
+---------------+---------+--------+------+--------+
| DATABASE_NAME | ORDINAL | HOST | PORT | ROLE |
+---------------+---------+--------+-------+--------+
| test | 3 | leaf-4 | 3306 | Master |
| test | 7 | leaf-4 | 3306 | Master |
+---------------+---------+--------+------+--------+
2 rows in set (0.01 sec)
-- test.x has 100 consecutive values from 1 to 100
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| min(id) | max(id) | count(*) |
+---------+---------+----------+
| 1 | 100 | 100 |
+---------+---------+----------+
1 row in set (0.00 sec)
If we kill the MemSQL instance on leaf-4, then leaf-4 will transition to offline in SHOW LEAVES, and partitions 3 and 7 will be unmapped on test.
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | NULL | NULL | online | 2 | 0.414 |
| leaf-2 | 3306 | 1 | NULL | NULL | online | 2 | 0.341 |
| leaf-3 | 3306 | 1 | NULL | NULL | online | 2 | 0.358 |
| leaf-4 | 3306 | 1 | NULL | NULL | offline | 0 | NULL |
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
4 rows in set (0.00 sec)
memsql> SHOW PARTITIONS ON test;
+---------+--------+-------+--------+
| Ordinal | Host | Port | Role |
+---------+--------+-------+--------+
| 0 | leaf-1 | 3306 | Master |
| 1 | leaf-2 | 3306 | Master |
| 2 | leaf-3 | 3306 | Master |
| 3 | NULL | NULL | NULL |
| 4 | leaf-1 | 3306 | Master |
| 5 | leaf-2 | 3306 | Master |
| 6 | leaf-3 | 3306 | Master |
| 7 | NULL | NULL | NULL |
+---------+--------+-------+--------+
8 rows in set (0.00 sec)
The database is now offline for reads and writes:
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
ERROR 1777 (HY000): Partition test:3 has no master instance.
After restarting MemSQL on leaf-4, master aggregator will notice the leaf is reachable again and attach it back to the cluster. Leaf will automatically transition to the online state, and all the partitions on the leaf will be automatically imported.
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | NULL | NULL | online | 4 | 0.437 |
| leaf-2 | 3306 | 1 | NULL | NULL | online | 4 | 0.411 |
| leaf-3 | 3306 | 1 | NULL | NULL | online | 4 | 0.366 |
| leaf-4 | 3306 | 1 | NULL | NULL | online | 1 | 0.418 |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
4 rows in set (0.00 sec)
-- The data that was on leaf-4 is back!
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| min(id) | max(id) | count(*) |
+---------+---------+----------+
| 1 | 100 | 100 |
+---------+---------+----------+
1 row in set (0.00 sec)
You can disable master aggregator from automatically moving leaves that become visible to the online state by running:
memsql> set global auto_attach = Off;
Query OK, 0 rows affected (0.00 sec)
In this case, after restarting MemSQL on leaf-4 and waiting for it to recover, instead of node being in offline state we will see it transitioning to a detached state:
-- leaf-4 is in the detached state
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | NULL | NULL | online | 1 | 0.467 |
| leaf-2 | 3306 | 1 | NULL | NULL | online | 1 | 0.359 |
| leaf-3 | 3306 | 1 | NULL | NULL | online | 1 | 0.405 |
| leaf-4 | 3306 | 1 | NULL | NULL | detached | 1 | 0.360 |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
4 rows in set (0.00 sec)
After that you can manually attach the leaf using ATTACH LEAF:
-- This will reintroduce leaf-4 into the system
memsql> attach leaf 'leaf-4': 3306;
Query OK, 1 row affected (0.52 sec)
-- leaf-4 is now online
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | NULL | NULL | online | 4 | 0.437 |
| leaf-2 | 3306 | 1 | NULL | NULL | online | 4 | 0.411 |
| leaf-3 | 3306 | 1 | NULL | NULL | online | 4 | 0.366 |
| leaf-4 | 3306 | 1 | NULL | NULL | online | 1 | 0.418 |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
4 rows in set (0.00 sec)
-- ATTACH LEAF imported partitions 3 and 7 from leaf-4
memsql> SHOW REBALANCE STATUS ON test;
+------------------+---------+-------------+-------------+-------+---------+--------------+
| Action | Ordinal | Target_Host | Target_Port | Phase | Status | Running_Time |
+------------------+---------+-------------+-------------+-------+---------+--------------+
| ATTACH PARTITION | 3 | leaf-4 | 3306 | 1 | success | 1 |
| ATTACH PARTITION | 7 | leaf-4 | 3306 | 1 | success | 3 |
+------------------+---------+-------------+-------------+-------+---------+--------------+
2 rows in set (0.00 sec)
-- The data that was on leaf-4 is back!
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| min(id) | max(id) | count(*) |
+---------+---------+----------+
| 1 | 100 | 100 |
+---------+---------+----------+
1 row in set (0.00 sec)
ATTACH LEAF In Redundancy-2
Let’s work through a full example of attaching a leaf back into a redundancy-2 cluster. This cluster has eight leaves: leaf-1 through leaf-8. You should understand leaf pairings before following along with this example: see Availability Groups for details.
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | leaf-5 | 3306 | online | 1 | 0.424 |
| leaf-2 | 3306 | 1 | leaf-6 | 3306 | online | 1 | 0.391 |
| leaf-3 | 3306 | 1 | leaf-7 | 3306 | online | 1 | 0.370 |
| leaf-4 | 3306 | 1 | leaf-8 | 3306 | online | 1 | 0.408 |
| leaf-5 | 3306 | 2 | leaf-1 | 3306 | online | 1 | 0.405 |
| leaf-6 | 3306 | 2 | leaf-2 | 3306 | online | 1 | 0.395 |
| leaf-7 | 3306 | 2 | leaf-3 | 3306 | online | 1 | 0.371 |
| leaf-8 | 3306 | 2 | leaf-4 | 3306 | online | 1 | 0.403 |
+--------+-------+--------------------+-----------+-----------+--------+--------------------+---------------------------+
8 rows in set (0.00 sec)
-- test.x has 100 consecutive values from 1 to 100
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| min(id) | max(id) | count(*) |
+---------+---------+----------+
| 1 | 100 | 100 |
+---------+---------+----------+
1 row in set (0.00 sec)
This is what a partition map might look like on the master aggregator before leaf-8 dies:
-- leaf-8 owns the master partition for test:3.
memsql> SELECT * FROM INFORMATION_SCHEMA.DISTRIBUTED_PARTITIONS
-> WHERE DATABASE_NAME='test' AND ORDINAL=3;
+---------------+---------+--------+------+--------+
| DATABASE_NAME | ORDINAL | HOST | PORT | ROLE |
+---------------+---------+--------+------+--------+
| test | 3 | leaf-8 | 3306 | Master |
| test | 3 | leaf-4 | 3306 | Slave |
+---------------+---------+--------+------+--------+
2 rows in set (0.00 sec)
After leaf-8 dies,
-- leaf-8 has entered the offline state.
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | leaf-5 | 3306 | online | 4 | 0.404 |
| leaf-2 | 3306 | 1 | leaf-6 | 3306 | online | 4 | 0.323 |
| leaf-3 | 3306 | 1 | leaf-7 | 3306 | online | 4 | 0.327 |
| leaf-4 | 3306 | 1 | leaf-8 | 3306 | online | 4 | 0.295 |
| leaf-5 | 3306 | 2 | leaf-1 | 3306 | online | 4 | 0.311 |
| leaf-6 | 3306 | 2 | leaf-2 | 3306 | online | 4 | 0.327 |
| leaf-7 | 3306 | 2 | leaf-3 | 3306 | online | 4 | 0.323 |
| leaf-8 | 3306 | 2 | leaf-4 | 3306 | offline | 1 | NULL |
+--------+-------+--------------------+-----------+-----------+---------+--------------------+---------------------------+
8 rows in set (0.00 sec)
-- leaf-4 now owns the master partition for test:3.
memsql> SELECT * FROM INFORMATION_SCHEMA.DISTRIBUTED_PARTITIONS
-> WHERE DATABASE_NAME='test' AND ORDINAL=3;
+---------------+---------+--------+------+--------+
| DATABASE_NAME | ORDINAL | HOST | PORT | ROLE |
+---------------+---------+--------+------+--------+
| test | 3 | leaf-4 | 3306 | Master |
+---------------+---------+--------+------+--------+
1 row in set (0.00 sec)
-- The data is still available because of the promotion on leaf-4.
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| min(id) | max(id) | count(*) |
+---------+---------+----------+
| 1 | 100 | 100 |
+---------+---------+----------+
1 row in set (0.00 sec)
-- We can also write to the database (the ... is an abbreviation, not valid SQL).
memsql> INSERT INTO test.x VALUES (101), (102), ... (200);
-- The new count is 200.
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| MIN(id) | MAX(id) | COUNT(*) |
+---------+---------+----------+
| 1 | 200 | 200 |
+---------+---------+----------+
1 row in set (0.00 sec)
If MemSQL is configured to automatically attach leaves that become reachable (by default it is), then after leaf-8 is restarted and recovered, it will automatically become online:
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | leaf-5 | 3306 | online | 4 | 0.396 |
| leaf-2 | 3306 | 1 | leaf-6 | 3306 | online | 4 | 0.323 |
| leaf-3 | 3306 | 1 | leaf-7 | 3306 | online | 4 | 0.321 |
| leaf-4 | 3306 | 1 | leaf-8 | 3306 | online | 4 | 0.320 |
| leaf-5 | 3306 | 2 | leaf-1 | 3306 | online | 4 | 0.319 |
| leaf-6 | 3306 | 2 | leaf-2 | 3306 | online | 4 | 0.329 |
| leaf-7 | 3306 | 2 | leaf-3 | 3306 | online | 4 | 0.327 |
| leaf-8 | 3306 | 2 | leaf-4 | 3306 | online | 1 | 0.318 |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
8 rows in set (0.00 sec)
And the database will become queryable.
After leaf-8 becomes visible, for some time it will be in the attaching state. During this period it is replicating new data for the partitions that are stored on leaf-4. As soon as it transitions to the online state, the redundancy is fully restored, however all the master partitions are still on leaf-4, meaning that it does all the work for the data stored on these partitions. Shortly after leaf-8 transitions to online state, half of the replica partitions on it will be promoted to masters, and the load will be evenly distributed again.
You can disable master aggregator from automatically moving leaves that become visible to the online state by running:
memsql> set global auto_attach = Off;
Query OK, 0 rows affected (0.00 sec)
In this case if the leaf becomes visible, it transitions to the detached state instead, and one needs to run ATTACH LEAF manually to move it to the online state.
ATTACH LEAF examines every partition database on a leaf and tries to reintroduce it into the system. If a database on the leaf conflicts with one of the partitions in the system, then ATTACH LEAF will return an error and request that you run it with the FORCE flag. For example, if partition 3 already has a master partition and the target leaf node has an online database matching partition 3, then ATTACH LEAF will return an error. The FORCE flag overrides this condition and will ignore the database on the target node, preferring the existing partition. This situation is common in redundancy-2.
After leaf-8 is recovered, it still has an online database for test:3. We can examine this by running SHOW DATABASES EXTENDED directly on the leaf:
-- This query is directly against the MemSQL instance on leaf-8.
memsql> SHOW DATABASES EXTENDED;
+--------------------+---------+-------------+-------------+----------+---------+-------------+------------+
| Database | Commits | Role | State | Position | Details | AsyncSlaves | SyncSlaves |
+--------------------+---------+-------------+-------------+----------+---------+-------------+------------+
| information_schema | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| memsql | 35 | master | online | 0:2005 | | 0 | 0 |
| test | 40 | async slave | replicating | 0:1723 | | 0 | 0 |
| test_11 | 0 | async slave | replicating | 0:10 | | 0 | 0 |
| test_15 | 0 | async slave | replicating | 0:10 | | 0 | 0 |
| test_3 | 0 | master | online | 0:10 | | 0 | 0 |
| test_7 | 0 | master | online | 0:10 | | 0 | 0 |
+--------------------+---------+-------------+-------------+----------+---------+-------------+------------+
7 rows in set (0.00 sec)
Back on the master aggregator,
-- leaf-8 is alive and is now in the detached state.
memsql> SHOW LEAVES;
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| Host | Port | Availability_Group | Pair_Host | Pair_Port | State | Opened_Connections | Average_Roundtrip_Latency |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
| leaf-1 | 3306 | 1 | leaf-5 | 3306 | online | 4 | 0.396 |
| leaf-2 | 3306 | 1 | leaf-6 | 3306 | online | 4 | 0.323 |
| leaf-3 | 3306 | 1 | leaf-7 | 3306 | online | 4 | 0.321 |
| leaf-4 | 3306 | 1 | leaf-8 | 3306 | online | 4 | 0.320 |
| leaf-5 | 3306 | 2 | leaf-1 | 3306 | online | 4 | 0.319 |
| leaf-6 | 3306 | 2 | leaf-2 | 3306 | online | 4 | 0.329 |
| leaf-7 | 3306 | 2 | leaf-3 | 3306 | online | 4 | 0.327 |
| leaf-8 | 3306 | 2 | leaf-4 | 3306 | detached | 1 | 0.318 |
+--------+-------+--------------------+-----------+-----------+----------+--------------------+---------------------------+
8 rows in set (0.00 sec)
-- This command will fail because test_3 on leaf-8 conflicts with the master partition
-- for test:3 on leaf-4.
memsql> attach leaf 'leaf-8':3306;
ERROR 1811 (HY000): Unable to attach leaf 'leaf-8':3306. Database `test_3` (which is in the 'Online' state) conflicts with an existing master instance of `test`:3 on 'leaf-4':3306. Use ATTACH LEAF ... FORCE to override this conflict.
-- ATTACH LEAF ... FORCE will ignore the test_3 database on leaf-8. The FORCE means
-- that you're okay with MemSQL potentially dropping the test_3 database on leaf-8
-- in the process of attaching the leaf.
memsql> attach leaf 'leaf-8':3306 FORCE;
Query OK, 1 row affected (12.92 sec)
-- The master partition for test:3 is once again on leaf-8
memsql> SELECT * FROM INFORMATION_SCHEMA.DISTRIBUTED_PARTITIONS
-> WHERE DATABASE_NAME='test' AND ORDINAL=3;
+---------------+---------+--------+------+--------+
| DATABASE_NAME | ORDINAL | HOST | PORT | ROLE |
+---------------+---------+--------+------+--------+
| test | 3 | leaf-8 | 3306 | Master |
| test | 3 | leaf-4 | 3306 | Slave |
+---------------+---------+--------+------+--------+
2 rows in set (0.00 sec)
-- After attaching leaf-8, the count remains at 200.
memsql> SELECT MIN(id), MAX(id), COUNT(*) FROM test.x;
+---------+---------+----------+
| MIN(id) | MAX(id) | COUNT(*) |
+---------+---------+----------+
| 1 | 200 | 200 |
+---------+---------+----------+
1 row in set (5.65 sec)
You can examine what operations the master aggregator performed for ATTACH LEAF with the SHOW REBALANCE STATUS command:
memsql> SHOW REBALANCE STATUS ON test;
+-------------------+---------+-------------+-------------+-------+---------+--------------+
| Action | Ordinal | Target_Host | Target_Port | Phase | Status | Running_Time |
+-------------------+---------+-------------+-------------+-------+---------+--------------+
| ATTACH PARTITION | 11 | leaf-8 | 3306 | 1 | success | 2185 |
| ATTACH PARTITION | 15 | leaf-8 | 3306 | 1 | success | 2226 |
| COPY PARTITION | 3 | leaf-8 | 3306 | 3 | success | 3096 |
| COPY PARTITION | 7 | leaf-8 | 3306 | 3 | success | 3097 |
| PROMOTE PARTITION | 3 | leaf-8 | 3306 | 7 | success | 4178 |
| PROMOTE PARTITION | 7 | leaf-8 | 3306 | 7 | success | 4181 |
| COPY PARTITION | 3 | leaf-4 | 3306 | 8 | success | 2768 |
| COPY PARTITION | 7 | leaf-4 | 3306 | 8 | success | 2813 |
+-------------------+---------+-------------+-------------+-------+---------+--------------+
8 rows in set (0.00 sec)
As mentioned above, the master aggregator will resolve the conflict on test:3 by preferring the master partition on leaf-4. In this example, the master aggregator erased the test_3 partition on leaf-8, copied over the data from leaf-4, and then promoted the partition on leaf-8.
A REBALANCE PARTITIONS walkthrough is left as an exercise for the reader: try adding two new leaves after the redundancy-2 summary and then running EXPLAIN REBALANCE PARTITIONS and REBALANCE PARTITIONS to distribute data onto the new nodes. Use SHOW PARTITIONS and SHOW LEAVES along the way to see how the data distribution changes after you run REBALANCE PARTITIONS.
Shutting Down and Restarting the Cluster
To avoid triggering automatic failure detection while cleanly shutting down the server, shut off and restart MemSQL instances in the correct order.
Shutting Down the Cluster
To avoid triggering failover detection:
-
Shut down the master aggregator first.
-
Shut down the remaining aggregators and leaves (in any order).
Restarting the Cluster
To bring the cluster back up:
-
Restart all of the leaves.
-
Verify that all the leaves are reachable (using a SELECT 1 query).
-
Turn on the master aggregator.
-
Turn on the remaining aggregators.
Synchronous vs. Asynchronous High Availability
When creating a database, you can choose whether the replica partitions are replicated synchronously or asynchronously. The syntax is outlined in CREATE DATABASE.
Asynchronous High Availability
By default, replica partitions are replicated asynchronously, meaning that transactions are first committed on the master partitions and subsequently replicated to the replica partitions.
From a user standpoint, this implies that when a SQL transaction commits, there is no guarantee that the transaction has already propagated to the replica partitions. While this allows for maximally performant high-throughput OLTP workloads, there is a probability that when a leaf dies, the latest (or “hot”) transactions might be lost if they have not yet replicated to the replica partitions on its pair leaf.
Synchronous High Availability
If stronger consistency guarantees are required, we recommend creating databases with synchronous high availability, as explained in CREATE DATABASE. In this mode, when a transaction commits on the master partitions, it is also guaranteed to have committed on the replica partitions. While this might negatively impact insert performance, it ensures that no transactions are lost in the event of a leaf failover.
Auto-healing
MemSQL handles most leaf failure scenarios automatically so that your workload never has to stop or get interrupted when running with high availability. Some scenarios that are covered by MemSQL include:
- When a leaf fails or disconnects from the cluster, the replica partitions on its pair node automatically get promoted as master partitions and take over the workload
- When a leaf comes back online, it is automatically attached back to the cluster and the partitions are rebalanced such that the workload is as uniform as possible across all machines
- When a replica partition has fallen behind or has diverged from its master partition, it is automatically reprovisioned
- MemSQL handles near-OOM and near-out-of-disk situations gracefully through efficient resource management and client-side error reporting
When leaf node recovers in redundancy level 1, it is immediately attached to the cluster. In contrast, attaching a leaf in redundancy level 2 (high availability) can take up to 2 minutes. This is because MemSQL optimizes restarting leaf nodes by waiting for a batch of leaves to recover before restoring redundancy. This speeds up the process as rebalancing partitions is an expensive operation. As a result, SHOW PARTITIONS might not immediately show the leaves as online after a restart.
In rare circumstances, it might be necessary to troubleshoot a cluster using low-level clustering commands. For more information, consult Cluster Management Commands and Using Replication

